virtualization-virtio-vdpa
Introduction
For IO virtualization, A MM supports two well known models: Emulation of devices or Paravirtualization., like we see Qemu for emulation and virtio for paravirtualization, but both have performance issue, as guest os(guest driver) can’t access physical device directly, it must send IO to intermediate layer(VMM) firstly which reduces performance. there is another voice comes up:Can we assign HW resources directly to the VM? if we do, what extra work should support by CPU?
When a VM or a Guest is launched over the VMM, the address space that the Guest OS is provided as its physical address range, known as Guest Physical Address (GPA), may not be the same as the real Host Physical Address (HPA). DMA capable devices need HPA to transfer the data to and from physical memory locations, we need CPU can translate GPA to HPA when DMA happens, that’s what IOMMU does, DMA remapping(similar thing for interrupt as well, Interrupt remapping)
The VT-d DMA-remapping hardware logic in the chipset sits between the DMA capable peripheral I/O devices and the computer’s physical memory.
IOMMU allows virtual machines to have direct access to hardware I/O devices, such as network cards, storage controllers (HBAs), and GPUs.
vDPA
Virtual data path acceleration (vDPA) in essence is an approach to standardize the NIC SRIOV data plane using the virtio ring layout and placing a single standard virtio driver in the guest decoupled from any vendor implementation, while adding a generic control plane and SW infrastructure to support it.
with vDPA, Data plane goes directly from the NIC to the guest using the virtio ring layout(need IOMMU support from CPU). However each NIC vendor can now continue using its own driver (with a small vDPA add-on) and a generic vDPA driver is added to the kernel to translate the vendor NIC driver/control-plane to the virtio control plane.
A “vDPA device” means a type of device whose datapath complies with the virtio specification, but whose control path is vendor specific. like smartNIC(Mellox Bluefield).
vDPA devices can be both physically located on the hardware or emulated by software
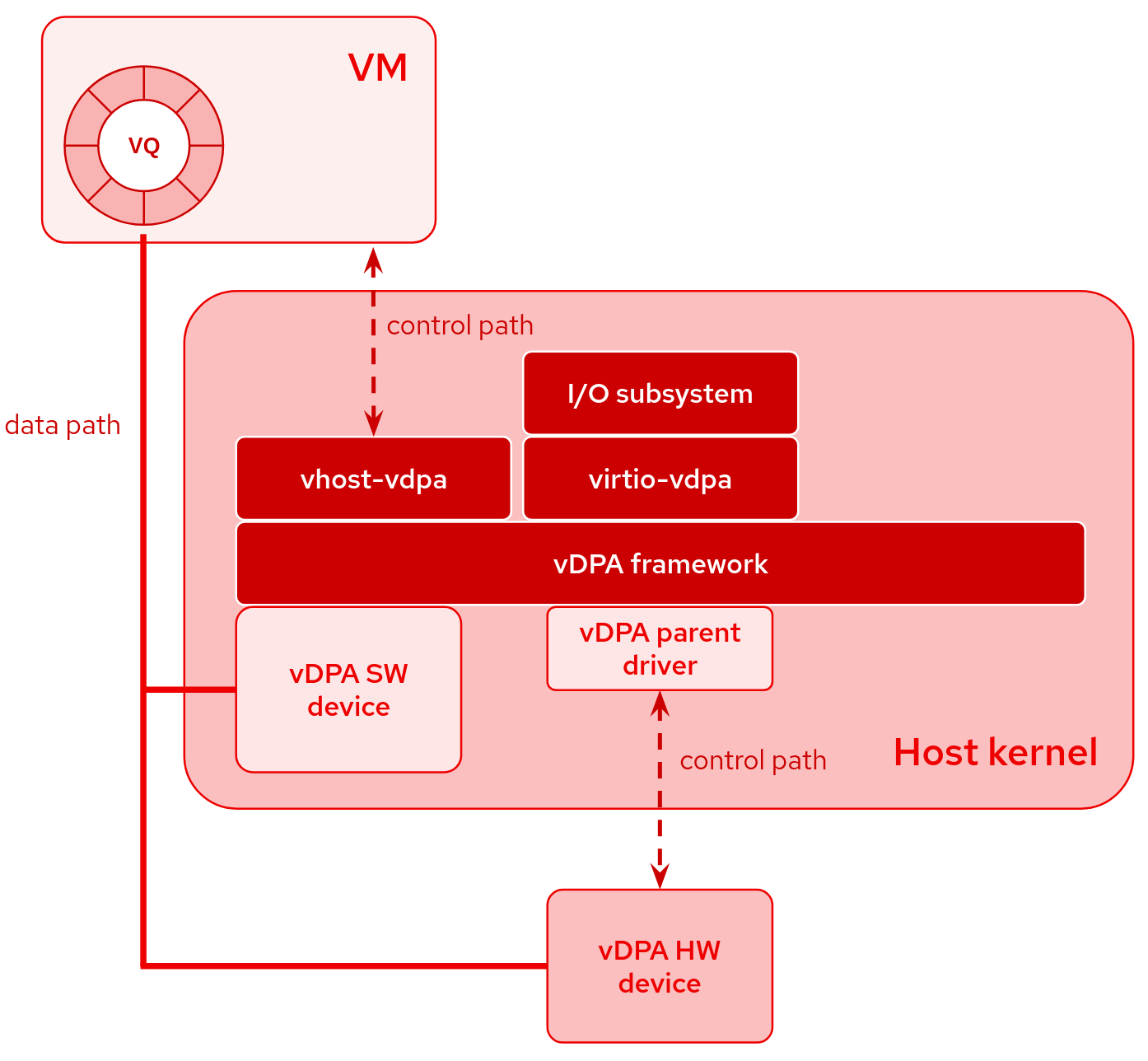
Passthrough with vDPA framework in kernel(can work also with vDPA in DPDK) and virtio-net-pmd can moved to guest kernel as well, it’s virtio-net
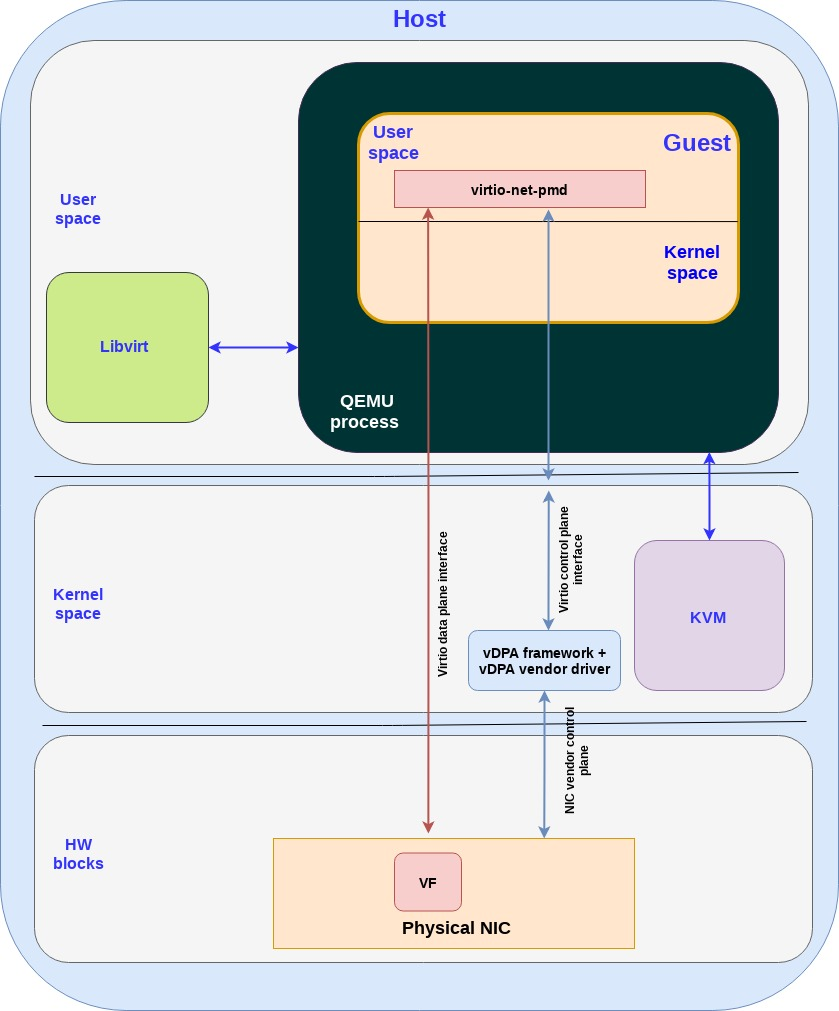
- In the VM use case since the QEMU exposes a virtio PCI device to the guest, the virtio-net-pmd will use PCI commands on the control plane and the QEMU will translate them to the vDPA kernel APIs (system calls).
Passthrough with vDPA framework for container!!!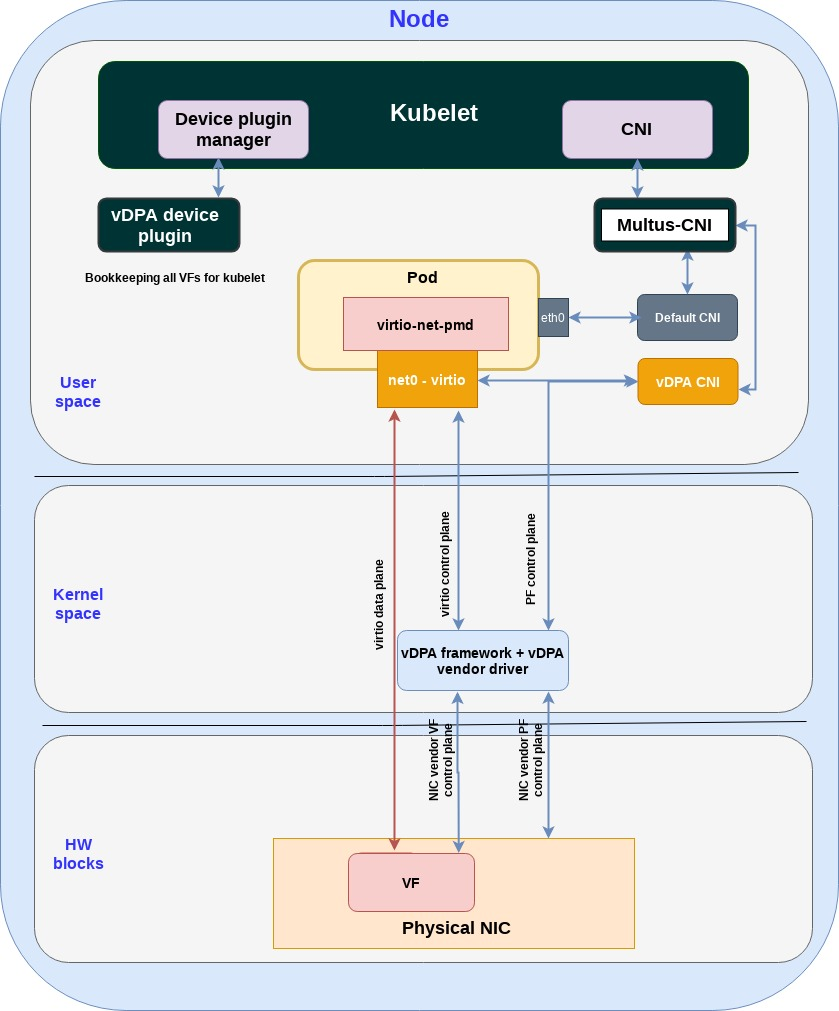
- In the container use case the virtio-net-pmd will invoke the vDPA kernel APIs (system calls) directly.
vDPA kernel framework
Here are some more details about vDPA kernel framework(actually vDPA firstly introduced in DPDK), Basic introduction about vDPA, please refer to vDPA basics.
Why vDPA kernel approach is required even DPDK already implement it?
Because there are a number of limitations for DPDK approach:
DPDK Library dependency on the host side is required for supporting this framework which is another dependency to take into account.
Since the vhost-user only provides userspace APIs, it can’t be connected to kernel subsystems. This means that the consumer of the vDPA interface will lose kernel functionality such as eBPF support.
Since DPDK focuses on the datapath then it doesn’t provide tooling for provisioning and controlling the HW. This also applies to the vDPA DPDK framework.
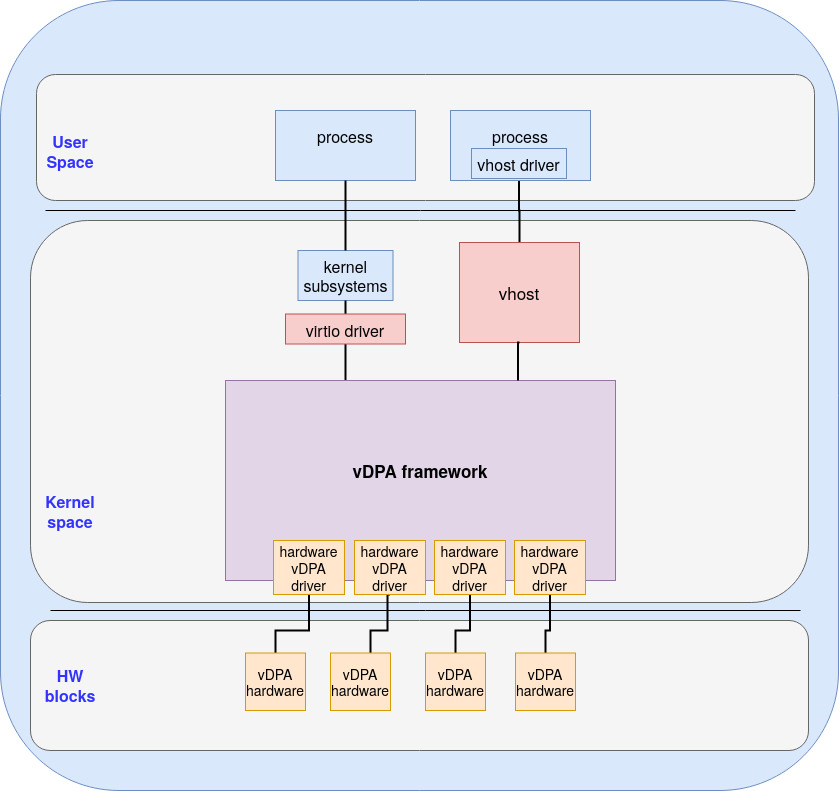
The vhost subsystem is the historical data path implementation of virtio inside the kernel. It was used for emulating the datapath of virtio devices on the HOST side. It exposes mature userspace APIs for setting up the kernel data path through vhost device (which are char devices). Various backends have been developed for using different types of vhost device (e.g. networking or SCSI). The vDPA kernel framework leverages these APIs through this subsystem for control plane
The virtio subsystem is the historical virtio kernel driver framework used for connecting guests/processes to a virtio device. It was used for controlling emulated virtio devices on the guest side. Usually we have the virtio device on the host and virtio driver on the guest which combine to create the virtio interface. This basically enables running applications that leverage vDPA (via the vhost subsystem) and those who do not (via the virtio subsystem) on the same physical vDPA NIC.
As you can see vDPA provides two ways to communicate with it
- One is from vhost(host kernel exposes a char device), user space can operate vDPA by this char device, like Qemu can uses vhost driver to operate vDPA device(control it).
- The other is from virtio driver, like Guest OS kernel uses virtio-net as front end, virtio backend call vDPA to operate vDPA device.
By combining the vDPA framework and the vhost/virtio subsystems, kernel virtio drivers or userspace vhost drivers think they are controlling a vhost or virtio device while in practice it’s a vDPA device
vDPA framework is a generic layer, it calls vendor driver for controlling device, so for each device, there must be a vDPA driver(driver plugin which calls vendor driver) inside vDPA framework, a typical vDPA driver is required to implement the following capabilities for control plane.
Device probing/removing: Vendor specific device probing and removing procedure.
Interrupt processing: Vendor or platform specific allocation and processing of the interrupt.
vDPA device abstraction: Implement the functions that are required by the vDPA framework most of which are the translation between virtio control command, vendor specific device interface and registering the vDPA device to the framework
DMA operation: For the device that has its own DMA translation logic, it can require the framework to pass DMA mapping to the driver for implementing vendor specific DMA translation
Since the datapath is offloaded to the vDPA hardware, the hardware vDPA driver becomes thin and simple to implement. The userspace vhost drivers or kernel virtio drivers control and setup the hardware datapath via vhost ioctls or virtio bus commands (depending on the subsystem you chose). The vDPA framework will then forward the virtio/vhost commands to the hardware vDPA drivers which will implement those commands in a vendor specific way.
vDPA framework will also relay the interrupts from vDPA hardware to the userspace vhost drivers and kernel virtio drivers. Doorbell and interrupt passthrough will be supported by the framework as well to achieve the device native performance.
Inside vDPA kernel framework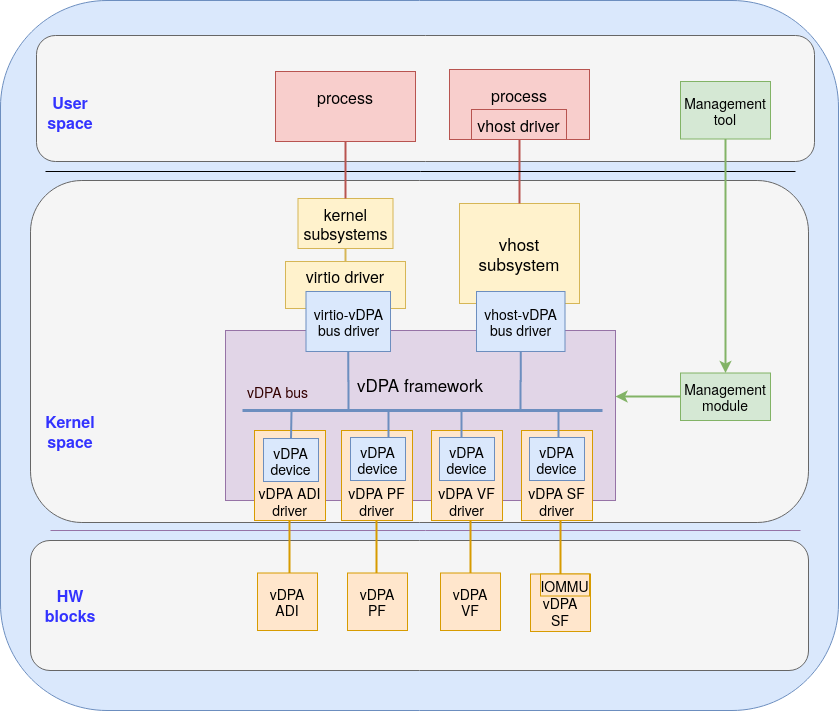
vhost-vDPA bus driver - This driver connects the vDPA bus to the vhost subsystem and presents a vhost char device to the userspace. This is useful for cases when the datapath is expected to bypass the kernel completely. Userspace drivers can control the vDPA device via vhost ioctls as if a vhost device. A typical use case is for performing direct I/O to userspace (or VM).
virtio-vDPA bus driver - This driver bridges the vDPA bus to a virtio bus and from there to a virtio interface. With the help of a virtio-vDPA bus driver, the vDPA device behaves as a virtio device so it can be used by various kernel subsystems such as networking, block, crypto etc. Applications that do not use vhost userspace APIs can keep using userspace APIs that are provided by kernel networking, block and other subsystems.
NOTE: a vdpa device can be bound to only one bus driver
FAQ
Which hardware vDPA devices are supported in Linux?
Currently upstream Linux contains drivers for the following vDPA devices:(these two drivers are also exported to dpdk(user driver) as well)
- virtio-net
- Intel IFC VF vDPA driver (CONFIG_IFCVF)
- Mellanox ConnectX vDPA driver (CONFIG_MLX5_VDPA_NET)
What are in-kernel vDPA device simulators useful for?
The vDPA device simulators are useful for testing, prototyping, and development of the vDPA software stack. Starting with layers in the kernel (e.g. vhost-vdpa), up to the VMMs.
The following kernel modules are currently available:
vdpa-sim-net (CONFIG_VDPA_SIM_NET)
- vDPA networking device simulator which loops TX traffic back to RX
vdpa-sim-blk (CONFIG_VDPA_SIM_BLK)