virtualization-vfio-sriov
VFIO
Virtual Function I/O is a framework for userspace I/O, it’s not limited to SRIOV, but SRIOV VF is the common use case.
The VFIO driver is an IOMMU/device agnostic framework for exposing direct device access to userspace, in a secure, IOMMU protected environment. In other words, this allows safe non-privileged, userspace drivers.
Why do we want that? Virtual machines often make use of direct device access (“device assignment”) when configured for the highest possible I/O performance. From a device and host perspective, this simply turns the VM into a userspace driver, with the benefits of significantly reduced latency, higher bandwidth, and direct use of bare-metal device drivers.
Summary
- Userspace driver interface(VFIO kernel module[vfio_pci] exposes PCI device resource to user by ioctl)
- Hardware IOMMU based DMA mapping and isolation
- IOMMU group based
- Modular IOMMU and bus driver support
- PCI and platform devices supported
- IOMMU API(type1) and ppc64 models
- Full device access, DMA and interrupt support
- read/write & mmap support of device resources
- Mapping of user memory to I/O virtual address
- eventfd and irqfd based signaling mechanisms
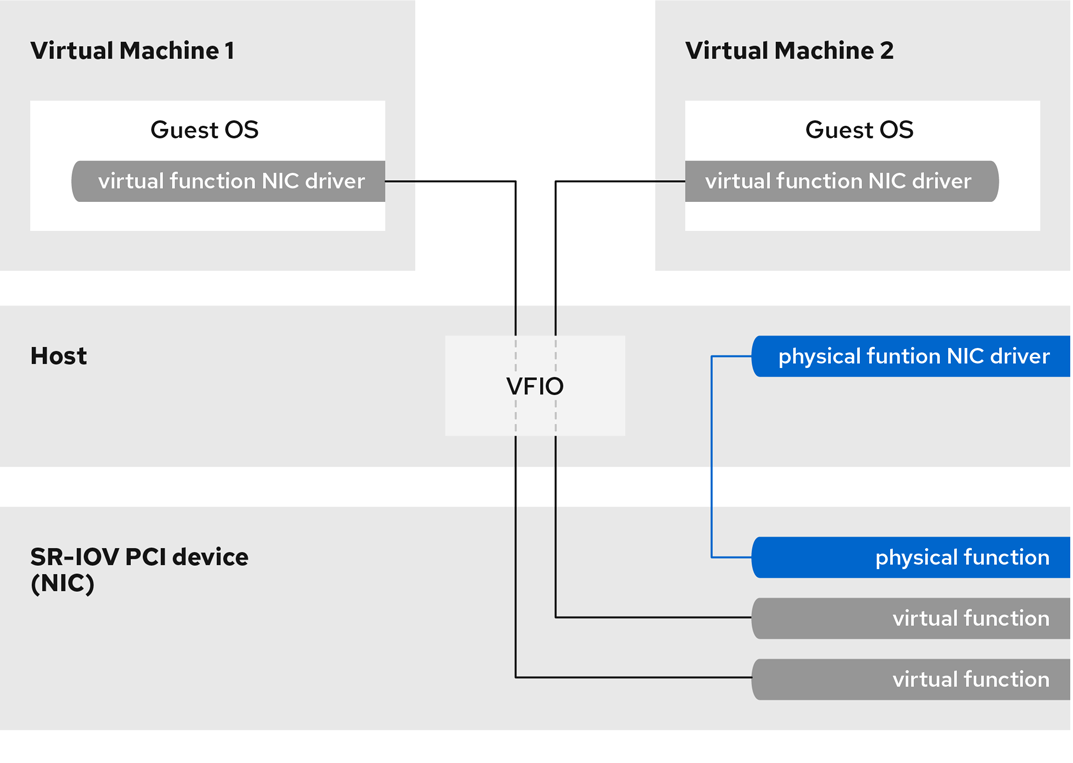
SRIOV
What is SR-IOV?
Single-root I/O virtualization (SR-IOV) is a specification that enables a single PCI Express (PCIe) device to present multiple separate PCI devices, called virtual functions (VFs), to the host system. Each of these devices:
- Is able to provide the same or similar service as the original PCIe device.
- Appears at a different address on the host PCI bus.
- Can be assigned to a different VM using VFIO assignment.
For example, a single SR-IOV capable network device can present VFs to multiple VMs. While all of the VFs use the same physical card, the same network connection, and the same network cable, each of the VMs directly controls its own hardware network device, and uses no extra resources from the host.
How SR-IOV works
The SR-IOV functionality is possible thanks to the introduction of the following PCIe functions:
- Physical functions (PFs) - A PCIe function that provides the functionality of its device (for example networking) to the host, but can also create and manage a set of VFs. Each SR-IOV capable device has one or more PFs.
- Virtual functions (VFs) - Lightweight PCIe functions that behave as independent devices. Each VF is derived from a PF. The maximum number of VFs a device can have depends on the device hardware. Each VF can be assigned only to a single VM at a time, but a VM can have multiple VFs assigned to it.
VMs recognize VFs as virtual devices. For example, a VF created by an SR-IOV network device appears as a network card to a VM to which it is assigned, in the same way as a physical network card appears to the host system.
Advantages
The primary advantages of using SR-IOV VFs rather than emulated devices are:
- Improved performance
- Reduced use of host CPU and memory resources
For example, a VF attached to a VM as a vNIC performs at almost the same level as a physical NIC, and much better than paravirtualized or emulated NICs. In particular, when multiple VFs are used simultaneously on a single host, the performance benefits can be significant.
Inconvenient
- To modify the configuration of a PF, you must first change the number of VFs exposed by the PF to zero. Therefore, you also need to remove the devices provided by these VFs from the VM to which they are assigned.
- A VM with an VFIO-assigned devices attached, including SR-IOV VFs, cannot be migrated to another host. In some cases, you can work around this limitation by pairing the assigned device with an emulated device. For example, you can bond an assigned networking VF to an emulated vNIC, and remove the VF before the migration.
- In addition, VFIO-assigned devices require pinning of VM memory, which increases the memory consumption of the VM and prevents the use of memory ballooning on the VM.
examples
1 | # if a device has SRIOV and we already set max vf number |
SRIOV driver
The SR-IOV drivers are implemented in the kernel. The core implementation is contained in the PCI subsystem, but there must also be driver support for both the Physical Function (PF) and Virtual Function (VF) devices.
- Intel 82599ES 10 Gigabit Ethernet Controller - uses the ixgbe driver
- Mellanox ConnectX-5 Ethernet Adapter Cards - use the mlx5_core driver
- Broadcom NetXtreme II BCM57810 - uses the bnx2x driver
1 |
|
NOTE
- SR-IOV VF network devices do not have permanent unique MAC addresses, then host reboot, mac is gone
- each vendor has it own SR-IOV VF driver
- SR-IOV not tight with vDPA(virtio Datapath Acceleration), vDPA device is a device that has virtio datapath support, SR-IOV can be enabled or disable(mostly enabled)
- vDPA device usually has SR-IOV capability, but device that has SR-IOV cap may not be a vDPA device.
IOMMU
Roles:
- Translation: I/O Virtual Address(IOVA) space
- Isolation: per device translation and invalid accesses blocked
DMA remapping
In a direct assignment model(Direct/IO), the guest OS device driver is in control of the device and is providing GPA instead of HPA required by the DMA capable device. DMA remapping hardware can be used to do the appropriate conversion. Since the GPA is provided by the VMM it knows the conversion from the GPA to the HPA. The VMM programs the DMA remapping hardware with the GPA to HPA conversion information so the DMA remapping hardware can perform the necessary translation. Using the remapping, the data can now be transferred directly to the appropriate buffer of the guests rather than going through an intermediate software emulation layer.

The basic idea of IOMMU DMA remapping is the same as the MMU for address translation. When the physical IO device do DMA, the address for DMA is called IOVA, IOMMU first using the device’s address(PCI BDF address) provided by PCI-E when raising interrupt(PCI device does not include this!!!) to find a page table(page table of domain) then using the the IOVA to walk this page table and finally get the host physical address. This is very like that how the MMU work to translate a virtual address to a physical address. Following figure show the basic idea of DMA remapping, this is the legacy mode, there is also a scalable mode, though the detail differs, the idea is the same.
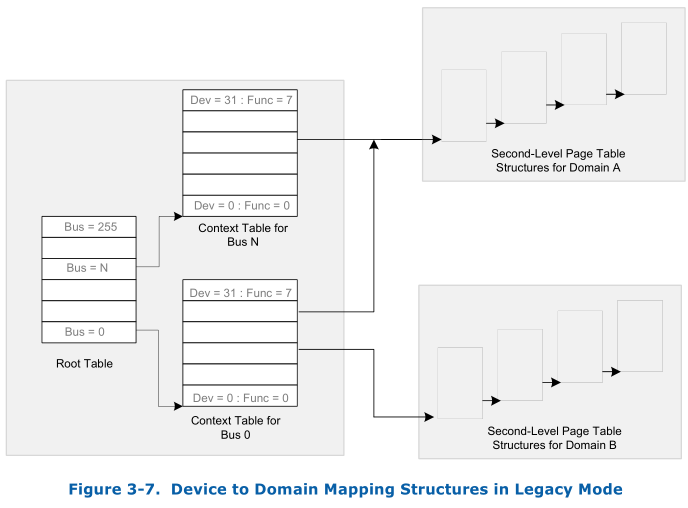
The device’s bus is useds to index in Root Table, the root table is 4-KByte in size and contains 256 root-entries. The root-table-entry contains the context-table pointer which references the context-table for all the devices on the bus identified by the root-entry.
A context-entry maps a specific I/O device on a bus to the domain to which it is assigned, and, in turn, to the address translation structures for the domain. Each context-table contains 256 entries, with each entry corresponding to a PCI device function on the bus. For a PCI device, the device and function numbers (lower 8-bits) are used to index into the context-table.
The root-table and context table is setup by the IOMMU driver, the page table is usually setup by the VMM. Of course, any process can do setup this page table. The IOVA is used as the input for the IOMMU translation, this address is device’s view address. The IOVA can be any address that is meaning for for the guest or process. For example, the qemu/kvm uses the GPA as the IOVA and also you can uses another address as the IOVA. The VFIO uses IOMMU to do the translation from GPA to HPA.
Interrupt remapping
IOMMU groups

VFIO uses IOMMU groups to isolate devices and prevent unintentional Direct Memory Access (DMA) between two devices running on the same host physical machine, which would impact host and guest functionality.
An IOMMU group is defined as the smallest set of devices that can be considered isolated from the IOMMU’s perspective, devices in the same group can be only assigned to same VM, devices in the same group use the same BDF as request ID when interrupted happens, VMM uses this request ID to identify VM and set proper IO page table of that VM, if devices in the same group are assigned to different machine, VMM can NOT know which IO page table to use to translated GPA to HPA.
Each IOMMU group may contain one or more devices. When multiple devices are present, all endpoints within the IOMMU group must be claimed for any device within the group to be assigned to a guest. This can be accomplished either by also assigning the extra endpoints to the guest or by detaching them from the host driver. Devices contained within a single group may not be split between multiple guests or split between host and guest. Non-endpoint devices such as PCIe root ports, switch ports, and bridges should not be detached from the host drivers and will not interfere with assignment of endpoints.
For endpoint devices within on IOMMU group, they must be in three cases
- all sits in host
- all assigned to only one vm
- part assigned to vm, the left detached from host driver
enable IOMMU steps for intel cpu
First make sure, intel cpu has vt-d support by looking lookup user guide.
- turn it on from BIOS as there is on vt-d switch there
- Then add ‘iommu=pt intel_iommu=on’ to boot parameter
1 | $ dmesg | grep IOMMU |
NOTE
- Devices assigned(PCI passthrough) need IOMMU supported, but no SRIOV required by that device
- In guest kernel, we should install proper driver for any passthrough device to make it work
- for normal device, we should install vendor specific driver, for VF device, we should install VF driver from that vendor, but if VF device(vdpa device) has virtio support from hardware, we can use virtio-net for it with vDPA framework to make it work.
- before we pass through a pci device, we should detach it from host(unbind it from original driver and bind it with
vfio-pcidriver)