linux-ansible-guide
Overview
Ansible is an open source IT automation engine that automates provisioning, configuration management, application deployment, orchestration, and many other IT processes.

Ansible works by connecting to your nodes and pushing out small programs—called modules—to these nodes. Modules are used to accomplish automation tasks in Ansible. These programs are written to be resource models of the desired state of the system. Ansible then executes these modules and removes them when finished.
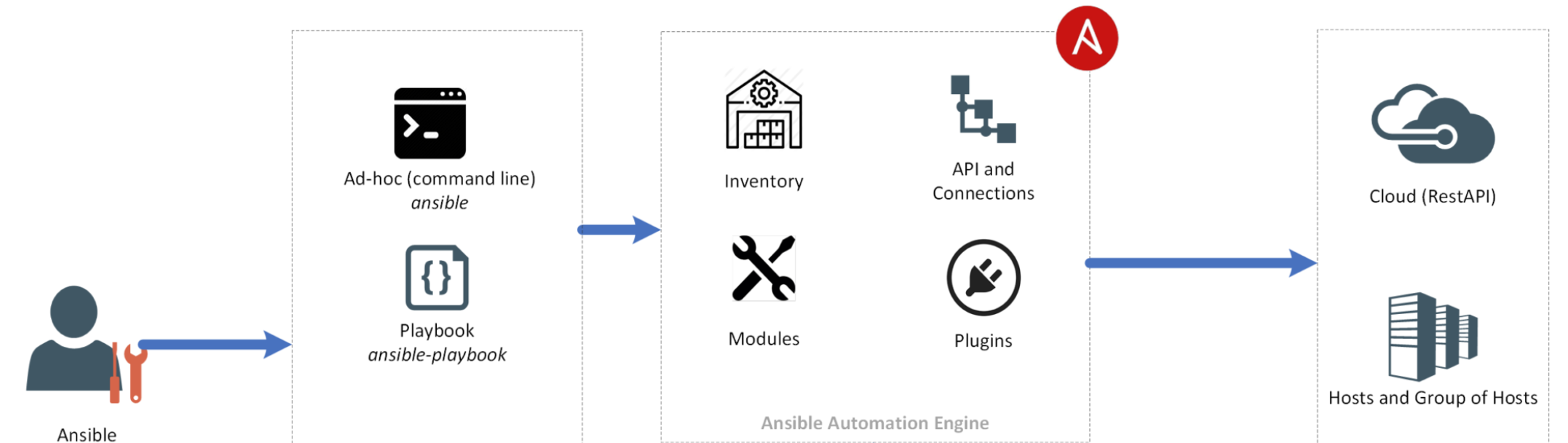
terminology:
- Control node: the host on which you use Ansible to execute tasks on the managed nodes
- Managed node: a host that is configured by the control node
- Host inventory: a list of managed nodes
- Ad-hoc command: a simple one-off task
- Playbook: a set of repeatable tasks for more complex configurations
- Module: code that performs a particular common task such as adding a user, installing a package, etc.
Concepts
1 | $ansible --version |
conf
default configuration file is /etc/ansible/ansible.cfg
The order in which a configuration file is located is as follow.
- ANSIBLE_CONFIG (environment variable)
- ansible.cfg (per directory)
- ~/.ansible.cfg (home directory)
- /etc/ansible/ansible.cfg (global)
All parameters of conf and conf example
1 | # dump the current setting |
inventory
The inventory file contains the IP address or DNS information about the list of managed hosts we want to work with.
Inventory file has a concept called grouping where you will be grouping your resources and run tasks against that group. You can create the inventory file without using groups. In this case, Ansible will use two default groups "all" and "ungrouped".
- ALL GROUP - All resources that are available in the inventory file by default will be assigned to all group.
- UNGROUPED - Resources that are not part of any user-defined groups will be automatically assigned to the ungrouped group
inventory path
default: /etc/ansible/hosts can be changed in the ansible.cfg Or by using the -i option on the ansible command
1 | $cat ansible.cfg |
inventory file example
1 | # must /etc/hosts for vm1, vm2, vm3 and vm4 |
modules
Modules (also referred to as “task plugins” or “library plugins”) are discrete units of code that can be used from the command line or in a playbook task. Ansible executes each module, usually on the remote managed node, and collects return values.
Each module supports taking arguments. Nearly all modules take key=value arguments, space delimited. Some modules take no arguments, and the command/shell modules simply take the string of the command you want to run.
Modules should be idempotent, and should avoid making any changes if they detect that the current state matches the desired final state. When used in an Ansible playbook, modules can trigger ‘change events’ in the form of notifying handlers to run additional tasks
1 | # module from command line |
Top modules ares file, include, template, command, service, shell, lineinfile, copy, yum, user, systemd, cron etc.
file: Creating different new files is a common task in the server scripts. In Ansible tools, you will find various methods for creating a new file. You can even set different group permission, assign an owner to the file; create a file with content, and more. It sets attributes of directories, symlinks, and files. Besides, it removes symlinks, directories, and file.ansible test-servers -m file -a 'path=/tmp/test state=directory mode=0755'
pingis used when we want to check whether the connection with our hosts defined in the inventory file is established or not.ansible test-servers -m ping
copy: The copy module is often used in writing playbooks when we want to copy a file(support directory as well) from a remote server to destination nodes.ansible test-servers -m copy -a 'src=/home/knoldus/Personal/blogs/blog3.txt dest=/tmp'ansible test-servers -m copy -a 'src=/home/knoldus/Personal/blogs dest=/tmp'
fetch: Ansible’s fetch module transfers files(not support directory) from a remote host to the local host. This is the reverse of the copy module.ansible test-servers -m fetch -a 'src=/var/log/nginx/access.log dest=fetched'
synchronize: Ansible’s fetch module to push/pull directoryansible all -m synchronize -a 'mode=pull src=/export/Data/xcgroup/persistence dest=fetched'pull src to local fetched/ansible all -m synchronize -a 'mode=push src=/export/Data/xcgroup/persistence dest=fetched'push src to remote fetched/
yum: We use the Yum module to install a service.ansible test-servers -m yum -a 'name=httpd,postfix state=present'
shell: When we want to run UNIX commands then we use shell moduleansible test-servers -m shell -a 'ls -la'
script: When we want to run a bunch of commands use script moduleansible test-servers -m script -a './test.sh'
service: When we want to ensure the state of a service that is service is running we use the service moduleansible test-servers -m service -a 'name=httpd state=started'
tempalte: The Template module is used to copy a configuration file from the local system to the host server. It is the same as the copy module, but it dynamically binds group variables defined by us.1
2
3
4
5
6
7
8
9
10
11- name: a play
hosts: all
gather_facts: no
vars:
variable_to_be_replaced: 'Hello world'
inline_variable: 'hello again.'
tasks:
- name: Ansible Template Example
template:
src: hello_world.j2 # in template, we can use var defined here
dest: /Users/mdtutorials2/Documents/Ansible/hello_world.txtlineinfile: this is generally used toalter or remove the existing line, insert line, and to replace the lines. Let’s know about the process to insert a line. You can set the file’s path to modify using the path/ dest parameter. You can insert lines through the line parameter. The line enters to the EOF. However, if the line is already there in the system, it won’t be added.ansible test-servers -m lineinfile -a 'path=/etc/selinux/config regexp=^SELINUX= line=SELINUX=enforcing'
replace: The replace module replaces all instances of a defined string within a file.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15- hosts: 127.0.0.1
tasks:
- name: Ansible replace string example
replace:
path: /etc/ansible/sample.txt
regexp: 'Unix'
replace: "Linux"
- hosts: 127.0.0.1
tasks:
- name: Ansible replace string example
replace:
path: /etc/hosts
regexp: '(\s+)server\.myubuntu\.com(\s+.*)?$'
replace: '\1server.linuxtechi.info\2' # use captured tokensinclude: When we want to include another playbook in our playbook, then we use the Include moduleuser: To add a particular user to our module we can use User module
Ad-Hoc
You can also use Ansible to run ad-hoc commands. To do this, you will need to run a command or call a module directly from the command line. No playbook is used. This is fine for a one time task.
1 | # command format |
PlayBook(suggested way)
A playbook runs in order from top to bottom. Within each play, tasks also run in order from top to bottom. Playbooks with multiple ‘plays’ can orchestrate multi-machine deployments, running one play on your webservers, then another play on your database servers, then a third play on your network infrastructure, and so on.
Plays consist of an ordered set of tasks to execute against host selections from your Ansible inventory file. Tasks are the pieces that make up a play and call Ansible modules. In a play, tasks are executed in the order in which they are written.
Ansible includes a “check mode” which allows you to validate playbooks and ad-hoc commands before making any state changes on a system. This shows you what Ansible would do, without actually making any changes. Handlers in Ansible are used to run a specific task only after a change has been made to the system. They are triggered by tasks and run once, at the end of all of the other plays in the playbook
playbook handlers
By default, handlers run after all the tasks in a particular play have been completed. Notified handlers are executed automatically after each of the following sections, in the following order: pre_tasks, roles/tasks and post_tasks. This approach is efficient, because the handler only runs once, regardless of how many tasks notify it. For example, if multiple tasks update a configuration file and notify a handler to restart Apache, Ansible only bounces Apache once to avoid unnecessary restarts.
1 | # basic playbook |
conditional task
Run a task only when condition is matched, condition can be custom variable, ansible built-in variable, or result of another task.
1 | - hosts: webservers |
For more keyword that’s available in playbook, refer to playbook keywords
Error Handling In Playbooks
Ignoring Failed Commands
Generally playbooks will stop executing any more steps on a host that has a task fail. Sometimes, though, you want to continue on. To do so, write a task that looks like this. This feature only works when the task must be able to run and return a value of ‘failed’, ignore_errors still print error output but continue to run next one. but as even fails, it continues to run next task if next task depends on result of the failed task, the result may not be the object descripted in module doc. as the command may be not run on the node at all. but if no ignore error, the result used in next task is always the one expected as otherwise it does not run if the previous one fails.
1 | - name: this will not be counted as a failure |
Handlers and Failure
When a task fails on a host, handlers which were previously notified will not be run on that host. This can lead to cases where an unrelated failure can leave a host in an unexpected state. For example, a task could update a configuration file and notify a handler to restart some service. If a task later on in the same play fails, the service will not be restarted despite the configuration change.
You can change this behavior with the --force-handlers command-line option, or by including force_handlers: True in a play, or force_handlers = True in ansible.cfg. When handlers are forced, they will run when notified even if a task fails on that host.
Controlling What Defines Failure
Ansible lets you define what “failure” means in each task using the failed_when conditional. As with all conditionals in Ansible, lists of multiple failed_when conditions are joined with an implicit and, meaning the task only fails when all conditions are met. If you want to trigger a failure when any of the conditions is met, you must define the conditions in a string with an explicit or operator.
1 | - name: Fail task when the command error output prints FAILED |
Overriding The Changed Result
When a shell/command or other module runs it will typically report “changed” status based on whether it thinks it affected machine state.
Sometimes you will know, based on the return code or output that it did not make any changes, and wish to override the “changed” result such that it does not appear in report output or does not cause handlers to fire:
1 | tasks: |
debug module
This module prints statements during execution and can be useful for debugging variables or expressions without necessarily halting the playbook.
Parameters
- msg: The customized message that is printed. If omitted, prints a generic message.
- var: A variable name to debug.
Mutually exclusive with the msgoption. Be aware that this option already runs in Jinja2 context and has an implicit{{ }}wrapping, so you should not be using Jinja2 delimiters unless you are looking for double interpolation. - verbosity: A number that controls when the debug is run, if you set to
3 it will only run debug when -vvv or above. Default: 0
1 | - name: Get uptime information |
Asynchronous Actions and Polling(task level)
Ansible runs tasks synchronously by default, if one task fails, the others does not run anymore. It keeps the connection to the remote node open until the task is completed. This means within a playbook, each task blocks the subsequent tasks until the current task completes.
Some of the long-running tasks could be
- Downloading a Big File from URL
- Running a Script known to run for a long time
- Rebooting the remote server and waiting for it to comeback
This may cause issue. Suppose you have a task in your playbook which takes more than say 10 minutes to execute. This means that the ssh connection between Ansible controller and the target machine should be stable for more than 10 minutes. It may take longer to complete than the SSH session allows for, causing a timeout. One can run the long-running process to execute in the background to perform other tasks concurrently.
To avoid blocking or timeout issues, you can use asynchronous mode to run all of your tasks at once and then poll until they are done.
To enable Asynchronous mode within Ansible playbook we need to use few parameters such as async, poll.
async- async keyword’s value indicates thetotal time allowed to complete the task.Once that time is over the task will be marked as completed irrespective of the end result. Along with this async also sends the task in the background which can be verified later on its final execution status.poll- poll keyword allows us to track the status of the job which was invoked by async and running in the background. Its value decides how frequent it would check if the background task is completed or not.The Poll keyword is
auto-enabled whenever you use async and it has a default value as 10 seconds.When you use poll parameter’s value set to
positive Ansible will avoid connection timeouts but will still block the next task in your playbook, waiting until the async task either completes, fails or times out.
NOTE
- async without poll, default poll is 10s, set timeout for the task
- async with postive poll, same as above, it just sets timeout for the task
- async with poll == 0, really async,
the task marked finished immediately without waiting for it result!!, but if second task depends on first one(in a node), NOT use async!!!
1 | ##############--- set time out for a task ########################### |
Strategy
When running Ansible playbooks, you might have noticed that the Ansible runs every task on each node one by one, it will not move to another task until a particular task is completed on each node, which will take a lot of time, in some cases. By default, the strategy is set to “linear”, we can set it to free.
linear: run the first task of play on all nodes(forks), when the first task finished on all nodes, run the second tasks on all nodesfree: The nodes who finished the first task, can run the second task without waiting for host who is still running first task.a host that is slow or stuck on a specific task won’t hold up the rest of the hosts and tasks
1 | # play level |
NOTE
- if nodes has dependency, use linear, otherwise use free
freeonly speed up process for play with more than on tasks.
Python API(not frequently used)
FQA
Ansible playbook hangs during execution
Refer to why ansible hangs
- SSH timeout
- command hangs in remote node
speed up playbook
NameError: name ‘temp_path’ is not defined
In such case, task does not run at all, this is probably there is no disk space on remote node as ansible need to copy module to remote host at /root/.ansible/tmp
change remote_tmp
remote_tmp is set by ansible.cfg
1 | $cat /etc/ansible/ansible.cfg |
get verbose output
Something if gathering is false, it’s hard to see why it fails, in this case, turn it on and run your playbook with -vvv or -vvvv
1 | $cat ansible.cfg |
set python interpreter at remote node
As ansible copies python module to remote and runs it at remote node, so that the remote python interpreter should be compatible with the module copied from control node.
1 | # check python on control node where you run ansible to see what python script that is for module |
Cannot handle SSH host authenticity prompts for multiple hosts
1 | $ ansible-playbook -i conf/app/south.host ./playbook/app/check_file.yml |
Solution
edit ansible.cfg with host_key_checking = false
1 | [defaults] |
forks vs serial vs async
- Serial sets a number, a percentage, or a list of numbers of hosts you want to manage at a time.
- Async triggers Ansible to run the task in the background which can be checked (or) followed up later, and
its value will be the maximum time that Ansible will wait for that particular Job (or) task to complete before it eventually times out or complete. - Ansible works by spinning off forks of itself and talking to many remote systems independently. The forks parameter controls how many hosts are configured by Ansible in parallel.
Suggestion
SERIAL : Decides the number of nodes process in each tasks in a single run.
Use: When you need to provide changes as batches/ rolling changes.
FORKS : Maximum number of simultaneous connections Ansible made on each Task.
Use: When you need to manage how many nodes should get affected simultaneously.
serial example
By default, with serial set, failing all servers(max fail percentage 100%) from one batch(serial value) will stop whole playbook to run even if there are some servers left in inventory, but this can be tunned with max_fail_percentage.
1 |
|
In the above example, if we had 6 hosts in the group ‘webservers’, Ansible would execute the play completely (both tasks) on 3 of the hosts before moving on to the next 3 hosts:
1 | PLAY [webservers] **************************************** |
without serial
1 |
|
1 | PLAY [webservers] **************************************** |
with large hosts, forks are decreasing after a while
With large hosts say 10000+, even set forks with larger number say 64, the ansible creates almost that number, but after a while if you check with ps -ef | grep ansible, the number becomes smaller and smaller with time to solve this
- use
serial(in playbook) to split hosts into small batches. - split hosts into several files outside
1 |
|
1 | $ ansible-playbook -i large_host ./playbook/with_serial_enabled.yml |
compare stdout with number
As stdout is a string, like "45", you have to convert it to int to compare it with nubmer
1 | - name: check process fd |