go-lib
std
strings
Package strings implements simple functions to manipulate UTF-8 encoded strings.
1 | - func Contains(s, substr string) bool |
Note
- Trim, TrimLeft, TrimRight, check ‘each character’ in the cutset
- TrimSuffix, TrimPrefix check ‘suffix and prefix’ as a whole not a set”
1 | package main |
string: no C K dno
hasprefix: true, hassuffix: true
split by `o`: [n C K dn ], fields(split by space): [no C K dno]
lower: no c k dno, upper: NO C K DNO, title: No C K Dno
contains?: true
trim: C K d, left: C K dno, right: no C K d, prefix: C K dno
bytes(manipulation of byte slices)
Package bytes implements functions for the manipulation of byte slices. It is similar to the facilities of the strings package.
Package strings implements simple functions to manipulate UTF-8 encoded strings.
1 | - func Contains(b, subslice []byte) bool |
container(list)
Package list implements a doubly linked list.
1 | import ( |
{a}
{b}
{c}
{d}
1
2
3
4
regex
Package regexp implements regular expression search.
There are 16 methods of Regexp that match a regular expression and identify the matched text. Their names are matched by this regular expression:Find(All)?(String)?(Submatch)?(Index)?
If ‘All’ is present, the routine matches successive non-overlapping matches of the entire expression. Empty matches abutting a preceding match are ignored. The return value is a slice containing the successive return values of the corresponding non-'All' routine. These routines take an extra integer argument, n. If n >= 0, the function returns at most n matches/submatches; otherwise, it returns all of them.
If ‘String’ is present, the argument is a string; otherwise it is a slice of bytes; return values are adjusted as appropriate.
If ‘Submatch’ is present, the return value is a slice identifying the successive submatches of the expression. Submatches are matches of parenthesized subexpressions (also known as capturing groups) within the regular expression, numbered from left to right in order of opening parenthesis. Submatch 0 is the match of the entire expression, submatch 1 the match of the first parenthesized subexpression, and so on.
If ‘Index’ is present, matches and submatches are identified by byte index pairs within the input string: result[2n:2n+1] identifies the indexes of the nth submatch. The pair for n==0 identifies the match of the entire expression. If ‘Index’ is not present, the match is identified by the text of the match/submatch. If an index is negative or text is nil, it means that subexpression did not match any string in the input. For ‘String’ versions an empty string means either no match or an empty match.
1 |
|
Frequently used
*func (re Regexp) FindString(s string) string
- FindString returns a string holding the text of the leftmost match in s of the regular expression. If there is no match, the return value is an empty string, but it will also be empty if the regular expression successfully matches an empty string. Use FindStringIndex or FindStringSubmatch if it is necessary to distinguish these cases.
*func (re Regexp) FindStringIndex(s string) (loc []int)
- FindStringIndex returns
a two-element slice of integersdefining the location of the leftmost match in s of the regular expression. The match itself is at s[loc[0]:loc[1]]. A return value of nil indicates no match.
- FindStringIndex returns
*func (re Regexp) MatchString(s string) bool
- MatchString reports whether the string s contains any match of the regular expression re.
*func (re Regexp) ReplaceAllLiteralString(src, repl string) string
- ReplaceAllLiteralString returns a copy of src, replacing matches of the Regexp with the replacement string repl. The replacement repl is substituted directly, without using Expand
*func (re Regexp) ReplaceAllString(src, repl string) string
- ReplaceAllString returns a copy of src, replacing matches of the Regexp with the replacement string repl. Inside repl,
$ signs are interpreted as in Expand, so for instance $1 represents the text of the first submatch.
- ReplaceAllString returns a copy of src, replacing matches of the Regexp with the replacement string repl. Inside repl,
*func (re Regexp) FindStringSubmatch(s string) []string
- FindStringSubmatch returns a two-element slice of strings holding the text of the leftmost match of the regular expression in s and the matches, if any, of its subexpressions, as defined by the ‘Submatch’ description in the package comment. A return value of nil indicates no match.
*func (re Regexp) FindStringSubmatchIndex(s string) []int
- FindStringSubmatchIndex returns a two-element slice holding the index pairs identifying the leftmost match of the regular expression in s and the matches, if any, of its subexpressions, as defined by the ‘Submatch’ and ‘Index’ descriptions in the package comment. A return value of nil indicates no match.
1 | package demo_regex |
"food"
""
[3 7]
[]
true
false
-ab-T-
-ab-${1}-
-ab-T-
-ab-xx-
[axxb xx]
[4 8 5 7]
exec(run shell from go)
Package exec runs external commands. It wraps os.StartProcess to make it easier to remap stdin and stdout, connect I/O with pipes, and do other adjustments.
Unlike the “system” library call from C and other languages, the os/exec package intentionally does not invoke the system shell and does not expand any glob patterns or handle other expansions, pipelines, or redirections typically done by shells. The package behaves more like C’s “exec” family of functions. To expand glob patterns, either call the shell directly, taking care to escape any dangerous input, or use the path/filepath package’s Glob function. To expand environment variables, use package os’s ExpandEnv.
sync method, goroutine blocks
- cmd.Run(): output is saved to cmd.Stdout and cmd.Stderr, by default discard, you can set them with buffer to get the output
- cmd.Output(): only return stdout
- cmd.CombinedOutput(): return stdout and stderr
async method
- func (c *Cmd) Start() error
Start starts a separate process to run the specified command but does not wait for it to complete. If Start returns successfully, the c.Process field will be set. A child process to run command
The Wait method will return the exit code and release associated resources once the command exits.
- func (c *Cmd) Wait() error
Wait waits for the command to exit and waits for any copying to stdin or copying from stdout or stderr to complete.
The command must have been started by Start.
1 | package main |
discard output
1 | package main |
'ls' executable is in '/usr/bin/ls'
print output to console
1 | package main |
total 476K
drwxr-xr-x 4 root root 165 Jul 1 17:23 .
drwxr-xr-x 16 root root 242 May 30 16:48 ..
drwxr-xr-x 3 root root 54 Jul 1 15:07 debug
-rw-r--r-- 1 root root 102K Jul 1 09:18 go_advanced.ipynb
-rw-r--r-- 1 root root 105K Jul 1 14:42 Go_basics.ipynb
-rw-r--r-- 1 root root 13K Jun 30 11:27 go-context.ipynb
-rw-r--r-- 1 root root 185K Jul 1 17:23 Go_lib.ipynb
-rw-r--r-- 1 root root 57K Jun 30 10:23 Go_network_rpc.ipynb
drwxr-xr-x 2 root root 181 Jun 30 11:08 .ipynb_checkpoints
capture output(stdout/stderr) with one buffer
1 | package main |
out:
total 476K
drwxr-xr-x 4 root root 165 Jul 1 17:23 .
drwxr-xr-x 16 root root 242 May 30 16:48 ..
drwxr-xr-x 3 root root 54 Jul 1 15:07 debug
-rw-r--r-- 1 root root 102K Jul 1 09:18 go_advanced.ipynb
-rw-r--r-- 1 root root 105K Jul 1 14:42 Go_basics.ipynb
-rw-r--r-- 1 root root 13K Jun 30 11:27 go-context.ipynb
-rw-r--r-- 1 root root 185K Jul 1 17:23 Go_lib.ipynb
-rw-r--r-- 1 root root 57K Jun 30 10:23 Go_network_rpc.ipynb
drwxr-xr-x 2 root root 181 Jun 30 11:08 .ipynb_checkpoints
capture output(stdout and stderr) with two buffer
1 | package main |
out:
total 476K
drwxr-xr-x 4 root root 165 Jul 1 17:23 .
drwxr-xr-x 16 root root 242 May 30 16:48 ..
drwxr-xr-x 3 root root 54 Jul 1 15:07 debug
-rw-r--r-- 1 root root 102K Jul 1 09:18 go_advanced.ipynb
-rw-r--r-- 1 root root 105K Jul 1 14:42 Go_basics.ipynb
-rw-r--r-- 1 root root 13K Jun 30 11:27 go-context.ipynb
-rw-r--r-- 1 root root 185K Jul 1 17:23 Go_lib.ipynb
-rw-r--r-- 1 root root 57K Jun 30 10:23 Go_network_rpc.ipynb
drwxr-xr-x 2 root root 181 Jun 30 11:08 .ipynb_checkpoints
err:
capture output and with time out
Use exec.CommandContext(), the os/exec package handles checking the timeout and killing the process if it expires, user no need to kill the process by himself.
1 | package main |
Command timed out
run command as daemon
That means after c.Process starts, we should release it from parent, hence init takes it as its parent, command runs daemon.
1 | import "os/exec" |
repl.go:9:24: undefined "syscall" in syscall.SysProcAttr <*ast.SelectorExpr>
time
Package time provides functionality for measuring and displaying time.
1 | import "time" |
2022-07-01 17:23:20.113770275 +0800 CST m=+6926.821548718
Sunday
true
false
1656667400
Current time: 2022-07-01 17:23:21.124828279 +0800 CST m=+6927.832606722
Current time: 2022-07-01 17:23:22.124729486 +0800 CST m=+6928.832507925
Current time: 2022-07-01 17:23:23.124739482 +0800 CST m=+6929.832517925
Done!
Periodically timeout
func NewTicker(d Duration) *Ticker
- NewTicker returns a new Ticker containing a channel that will send the time on the channel after each tick. The period of the ticks is specified by the duration argument. The ticker will adjust the time interval or drop ticks to make up for slow receivers. The duration d must be greater than zero; if not, NewTicker will panic. Stop the ticker to release associated resources.
func Tick(d Duration) <-chan Time
- Tick is a convenience wrapper for NewTicker providing access to the ticking channel only. While Tick is useful for clients that have no need to shut down the Ticker, be aware that without a way to shut it down the underlying Ticker cannot be recovered by the garbage collector; it "leaks". Unlike NewTicker, Tick will return nil if d <= 0.
1 | import "time" |
current time: 2022-07-01 17:23:24.126393711 +0800 CST m=+6930.834172154
done
2022-07-01 17:23:25.12738211 +0800 CST m=+6931.835160502
2022-07-01 17:23:26.127205432 +0800 CST m=+6932.834983825
Once timeout
1 | import "time" |
timed out
timestamp
1 | package main |
2022-07-01 17:23:27.129936571 +0800 CST m=+6933.837715027
1656667407
1656667407129992154
2022-07-01 17:23:27 +0800 CST
2022-07-01 17:23:27
sorting with Go
Package sort provides primitives for sorting slices and user-defined collections, you can provides less function for custom types.
sort for int, float, string
1 | import ( |
[1 2 3 4 5 6] true
[Alpha Bravo Delta Gopher Grin]
sorting slice
Any type of slice, you must provide less functionfunc SliceStable(x interface{}, less func(i, j int) bool)func Slice(x interface{}, less func(i, j int) bool)
Slice sorts the slice x given the provided less function. It panics if x is not a slice.
The sort is not guaranteed to be stable: equal elements may be reversed from their original order. For a stable sort, use SliceStable.
The less function must satisfy the same requirements as the Interface type’s Less method.
Less reports whether the element with index i must sort before the element with index j, less returns true means i must be sorted firstly
1 | package main |
By name: [{Alice 55} {Bob 75} {Gopher 7} {Vera 24}]
By age: [{Gopher 7} {Vera 24} {Alice 55} {Bob 75}]
encoding
Package encoding defines interfaces shared by other packages that convert data to and from byte-level and textual representations. like encoding/xml encoding/base64 encoding/hex etc
base64
func (enc *Encoding) Decode(dst, src []byte) (n int, err error)
func (enc *Encoding) DecodeString(s string) ([]byte, error)
func (enc *Encoding) Encode(dst, src []byte)
func (enc *Encoding) EncodeToString(src []byte) string
hex
func Decode(dst, src []byte) (int, error)
func DecodeString(s string) ([]byte, error)
func Encode(dst, src []byte) int
func EncodeToString(src []byte) string
1 | import ( |
aGVsbG8=
hello
68656c6c6f
hello
json
Go supports encode/decode any type to/from json, but most of time, we use map or struct for json encoding and decoding.
Here are frequently used APIs provided by encoding/json package.
func Marshal(v interface{}) ([]byte, error)
Marshal traverses the value v
recursively.
Encoding Note
The encoding of each struct field can be customized by the format string stored under the “json” key in the struct field’s tag. The format string gives the name of the field, possibly followed by a comma-separated list of options. The name may be empty in order to specify options without overriding the default field name.
// Field appears in JSON as key “myName”.
Field intjson:"myName"
// Field appears in JSON as key “myName” and
// the field is omitted from the object if its value is empty,
// empty in GO means default value of each type
// integer: 0
// string: “”
// pointer: nil
// slice: has zero elements
// omitempty: means if it’s not set or set with default value, these fileds are not marshed or unmarshed!!!
Field intjson:"myName,omitempty"
// Field is ignored by this package.
Field intjson:"-"
The map’s key type must either be a string, an integer type
map[string]interface{} to store arbitrary JSON objects, []interface{} to store arbitrary JSON arrays.
Pointer values encode as the value pointed to. A nil pointer encodes as the null JSON value.
func MarshalIndent(v interface{}, prefix, indent string) ([]byte, error)
MarshalIndent is like Marshal but applies Indent to format the output. Each JSON element in the output will begin on a new line beginning with prefix followed by one or more copies of indent according to the indentation nesting.
func Unmarshal(data []byte, v interface{}) error
Unmarshal parses the JSON-encoded data and stores the result in the value pointed to by v
Unmarshal uses the inverse of the encodings that Marshal uses, allocating maps, slices, and pointers as necessary, If v is nil or not a pointer, Unmarshal returns an InvalidUnmarshalError.
To unmarshal JSON into a struct, Unmarshal matches incoming object keys to the keys used by Marshal (either the struct field name or its tag), preferring an exact match but also accepting a case-insensitive match. By default, object keys which don’t have a corresponding struct field are ignored.
map json key to struct field
- For a given JSON key Foo, Unmarshal will attempt to match the struct fields in this order:
- an exported (public) field with a struct tag json:”Foo”,
- an exported field named Foo, or
- an exported field named FOO, FoO, or some other case-insensitive match.
Only fields that are found in the destination type will be decoded, any unexported fields in the destination struct will be unaffected.
encode—> Marshal() —> to json string
decode—> Unmarshal() —> to struct or map
What to use (Structs vs maps)
As a general rule of thumb, if you can use structs to represent your JSON data, you should use them. The only good reason to use maps would be if it were not possible to use structs due to the uncertain nature of the keys or values in the data.
If we use maps, we will either need each of the keys to have the same data type, or use a generic type and convert it later.
NOTE
Only exported field are encode and marshaled
json.Marshal(obj), json.Marshal(&obj)both are okjson.Unmarshal(&obj)must use pointer as parameter, the pointer must not be nil!!!json.NewEncoder(os.Stdout).Encode(obj),json.NewEncoder(os.Stdout).Encode(&obj)both are ok, write encoded data from obj to os.Stdout.json.Decoder(os.Stdin).Decode(&obj)must use pointer as parameter, read decoded data from os.Stdin to objMarshal is used to encode struct/map to stringwhileEncode() is used to encode struct/map and write to io.Writer, similar thing happens for Unmarshal and Decode().You can Marshal from one struct, but Unmarshal to another struct, but only the ‘matched’ field are assigned, others use default, the ‘matched’ field must have same type!!! but the tag/name obeys above rules.
Sugestion for json.Decoder() vs json.Unmarshal()
use json.Decoder if your
data is coming from an io.Reader stream, or you need to decode multiple values from a stream of dataUse json.Unmarshal if you already have the JSON string in memory.
json.Decoder(io.Reader).Decode(&obj) blocks if no data available, returns if EOF, error or data available. if io.Reader is a file, it reads them all to buffer, then UnMarshal, if io.Reader is a connection, receives data then Unmarshal()
Marshal a string, just quoted them, “” is added
1 | s := "hello" |
1 | package main |
json string: {"Name":"tom","Id":100}
tom
1 | import ( |
{
"Name": "Standard",
"Fruit": [
"Apple",
"Banana",
"Orange"
],
"ref": 999,
"饞€竝rivate": "Second-rate",
"Created": "2022-07-01T17:23:27.137247781+08:00"
}
Standard [Apple Banana Orange] 999
2018-04-09 23:00:00 +0000 UTC
{Name:Standard Fruit:[Apple Banana Orange] Id:999 饞€竝rivate: Created:2018-04-09 23:00:00 +0000 UTC}
1 | import ( |
{
"Age": 6,
"Name": "Eve",
"Parents": [
"Alice",
"Bob",
12
]
}
map[capacity:40 name:battery sensor] battery sensor 40 float64
1 | package main |
{YourName:hi YourScore:100}
omitempty
If field is set to its default value, the key itself will be omitted from the JSON object. omitempty only works for Marshal() to string!!!
zero value(default) for each type
- 0 for numeric types,
- false for the boolean type
- “” (the empty string) for string.
- nil for pointer
- len(map) == 0
- len(slice) == 0
No default value for struct object, so omitempy has no effect for embeded object!!!
In cases where an empty value does not exist, omitempty is of no use. An embedded struct, for example, does not have an empty value:
1 | package main |
{"Breed":"pug","WeightKg":0,"Size":{"Height":0}}
In this case, even though we never set the value of the Size attribute, and set its omitempty tag, it still appears in the output. This is because structs do not have any empty value in Go. To solve this, use a struct pointer instead :
1 | package main |
{"Breed":"hal","WeightKg":0}
{"Breed":"cal","pweight":0}
{"Breed":"cal","weight":1}
json.marshal for built-in type
As you can json.Marshal() can be used for built-in type, the result is several bytes for that value, then you can Unmarshal to that type!
json.Marshal() for nil will result ‘null’ string
1 | package main |
[116 114 117 101]
true
============
[49 50]
12
============
[34 97 98 34]
"ab"
============
[91 34 97 34 44 34 98 34 93]
["a","b"]
============
[110 117 108 108]
null
============
xml
Marshalfunc Marshal(v any) ([]byte, error)
Marshal returns the XML encoding of v.
Marshal handles an array or slice by marshaling each of the elements. Marshal handles a pointer by marshaling the value it points at or, if the pointer is nil, by writing nothing. Marshal handles an interface value by marshaling the value it contains or, if the interface value is nil, by writing nothing. Marshal handles all other data by writing one or more XML elements containing the data.
The name for the XML elements is taken from, in order of preference:
- the
tag on the XMLName field, if the data is a struct - the
value of the XMLName fieldof type Name: the only one use value as name of element.!!! - the
tag of the struct fieldused to obtain the data - the
name of the struct fieldused to obtain the data - the
name of the marshaled type.
The XML element for a struct contains marshaled elements for each of the exported fields of the struct, with these exceptions:
- the XMLName field, described above, is omitted.
- a field with tag “-“ is omitted.
- a field with tag “name,attr” becomes an attribute with the given name in the XML element.
- a field with tag “,attr” becomes an attribute with the field name in the XML element.
- a field with tag “,chardata” is written as character data, not as an XML element.(field value used for struct, as no
<$tag></$tag>generated) - a field with tag “,cdata” is written as character data wrapped in one or more
<![CDATA[...]]>tags, not as an XML element. - a field with tag “,innerxml” is written verbatim, not subject to the usual marshaling procedure.
- a field with tag “,comment” is written as an XML comment, not subject to the usual marshaling procedure. It must not contain the “–” string within it.
- a field with a tag including the “omitempty” option is omitted if the field value is empty. The
empty values are false, 0, any nil pointer or interface value, and any array, slice, map, or string of length zero. - an anonymous struct field is handled as if the fields of its value were part of the outer struct.
- a field implementing Marshaler is written by calling its MarshalXML method.
- a field implementing encoding.TextMarshaler is written by encoding the result of its MarshalText method as text.
NOTE
If a field uses a tag “a>b>c”, then the element c will be nested inside parent elements a and b. Fields that appear next to each other that name the same parent will be enclosed in one XML element.
If the XML name for a struct field is defined by both the field tag and the struct’s XMLName field, the names must match.
Unmarshalfunc Unmarshal(data []byte, v any) error
Unmarshal parses the XML-encoded data and stores the result in the value pointed to by v, which must be an arbitrary struct, slice, or string. Well-formed data that does not fit into v is discarded.
Because Unmarshal uses the reflect package, it can only assign to exported (upper case) fields. Unmarshal uses a case-sensitive comparison to match XML element names to tag values and struct field names.
Unmarshal maps an XML element to a struct using the following rules. In the rules, the tag of a field refers to the value associated with the key ‘xml’ in the struct field’s tag
If the struct has a field of type []byte or string with tag “,innerxml”, Unmarshal accumulates the raw XML nested inside the element in that field. The rest of the rules still apply.
If the struct has a field named XMLName of type Name, Unmarshal records the element name in that field.
If the XMLName field has an associated tag of the form “name” or “namespace-URL name”, the XML element must have the given name (and, optionally, name space) or else Unmarshal returns an error.
If the XML element has an attribute whose name matches a struct field name with an associated tag containing “,attr” or the explicit name in a struct field tag of the form “name,attr”, Unmarshal records the attribute value in that field.
If the XML element has an attribute not handled by the previous rule and the struct has a field with an associated tag containing “,any,attr”, Unmarshal records the attribute value in the first such field.
If the XML element contains character data, that data is accumulated in the first struct field that has tag “,chardata”. The struct field may have type []byte or string. If there is no such field, the character data is discarded.
If the XML element contains comments, they are accumulated in the first struct field that has tag “,comment”. The struct field may have type []byte or string. If there is no such field, the comments are discarded.
If the XML element contains a sub-element whose name matches the prefix of a tag formatted as “a” or “a>b>c”, unmarshal will descend into the XML structure looking for elements with the given names, and will map the innermost elements to that struct field. A tag starting with “>” is equivalent to one starting with the field name followed by “>”.
If the XML element contains a sub-element whose name matches a struct field’s XMLName tag and the struct field has no explicit name tag as per the previous rule, unmarshal maps the sub-element to that struct field.
If the XML element contains a sub-element whose name matches a field without any mode flags (“,attr”, “,chardata”, etc), Unmarshal maps the sub-element to that struct field.
If the XML element contains a sub-element that hasn’t matched any of the above rules and the struct has a field with tag “,any”, unmarshal maps the sub-element to that struct field.
An anonymous struct field is handled as if the fields of its value were part of the outer struct.
A struct field with tag “-“ is never unmarshaled into.
NOTE
- If Unmarshal encounters a field type that implements the Unmarshaler interface, Unmarshal calls its UnmarshalXML method to produce the value from the XML element. Otherwise, if the value implements encoding.TextUnmarshaler, Unmarshal calls that value’s UnmarshalText method.
1 | package main |
<plant id="27">
<name>Coffee</name>
</plant>
==================================
<?xml version="1.0" encoding="UTF-8"?>
<plant id="27">
<name>Coffee</name>
</plant>
==================================
{{ plant} 27 Coffee []}
==================================
Coffee
Tomato
Mexico
California
#### chardata
In xml, mostly only the leaf node has value, leaf nodes can be defined by a field of struct, `the field type can be built-in type like int, string, leaf node without attr can use built-in type!!!`, like this:
1
2
3
4
5
6
type Garden struct {
Cool string `xml:"cool,omitempty"`
}
gd = Garden{}
gd.Cool = "jas"
The generate xml:
1
2
3
<Garden>
<cool>jas</cool>
</Garden>
What about if we want to add attr to cool, there is no way to do as, cool is built-in type, you can not add attr to it, you need to declare a struct, like this, as Value is chardata, not XML element, that means **`chardata is needed for leaf node that has attrs and its value`**
1
2
3
4
5
6
7
8
9
type CoolT {
Name string `xml:"name,attr"`
Value string `xml:",chardata"`
}
type Garden struct {
Cool string `xml:"cool,omitempty"`
}
gd = Garden{}
gd.Cool = "jas"
#### custom UnmarshalXML and MarshalXML
For user type, user can implement its own UnmarshalXML and marshalXML of that type, which is called by xml.Marshal() and xml.UnmarshalXML(), if you do not want to use the default logic of this process.
### gob
`Gob is like pickle in python and Protobuf`, they are used to serialize object, the serialized object is a stream which is self-describing(`have type, value, name et`c). `Each data item in the stream is preceded by a specification of its type, expressed in terms of a small set of predefined types`. Pointers are not transmitted, but the things they point to are transmitted; that is, the values are flattened. Nil pointers are not permitted, as they have no value. Recursive types work fine, but recursive values (data with cycles) are problematic. This may change.
To use gobs, create an Encoder and present it with a series of data items as values or addresses that can be dereferenced to values. The Encoder makes sure all type information is sent before it is needed. At the receive side, a Decoder retrieves values from the encoded stream and unpacks them into local variables.
The source and destination values/types `need not correspond exactly`. For structs, fields (identified by name) that are in the source but absent from the receiving variable will be ignored. Fields that are in the receiving variable but missing from the transmitted type or value will be ignored in the destination. **If a field with the same name is present in both, their types must be compatible**. Both the receiver and transmitter will do all necessary indirection and dereferencing to convert between gobs and actual Go values.
1
struct { A, B int }
can be sent from or received into any of these Go types below:
1
2
3
4
struct { A, B int } // the same
*struct { A, B int } // extra indirection of the struct
struct { *A, **B int } // extra indirection of the fields
struct { A, B int64 } // different concrete value type; see below
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
package main
import (
"bytes"
"encoding/gob"
"fmt"
"log"
)
type P struct {
X, Y, Z int
Name string
}
type Q struct {
X, Y *int32 // when decode from P, Z is ignored, int converted to int32
Name string
}
// This example shows the basic usage of the package: Create an encoder,
// transmit some values, receive them with a decoder.
func main() {
// Initialize the encoder and decoder. Normally enc and dec would be
// bound to network connections and the encoder and decoder would
// run in different processes but here is just a demo to show how it works !!!
var network bytes.Buffer // Stand-in for a network connection
enc := gob.NewEncoder(&network) // Will write to network.
dec := gob.NewDecoder(&network) // Will read from network.
// Encode (send) some values.
err := enc.Encode(P{3, 4, 5, "Pythagoras"}) // instance of P struct serialized to buffer.
if err != nil {
log.Fatal("encode error:", err)
}
err = enc.Encode(P{1782, 1841, 1922, "Treehouse"}) // another instance of P struct serialized to buffer.
if err != nil {
log.Fatal("encode error:", err)
}
// Decode (receive) and print the values. as it's stream first in, first out!!!
var q Q
err = dec.Decode(&q) //after decode, first instance is removed from stream.
if err != nil {
log.Fatal("decode error 1:", err)
}
fmt.Printf("%q: {%d, %d}\n", q.Name, *q.X, *q.Y)
err = dec.Decode(&q)
if err != nil {
log.Fatal("decode error 2:", err)
}
fmt.Printf("%q: {%d, %d}\n", q.Name, *q.X, *q.Y)
}
main()
"Pythagoras": {3, 4}
"Treehouse": {1782, 1841}
## hash(get hash value)
Package crc32 implements the 32-bit cyclic redundancy check, or CRC-32, checksum mostly `used for data transfer over network`.
`Package maphash` provides `hash functions on byte sequences`. These hash functions are intended to be used to implement hash tables or other data structures that need to `map arbitrary strings or byte sequences to a uniform distribution on unsigned 64-bit integers`. Each different instance of a hash table or data structure should use its own Seed.
**maphash API**
- func (h *Hash) Sum64() uint64
- func (h *Hash) Write(b []byte) (int, error)
- func (h *Hash) WriteString(s string) (int, error)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import "hash/crc32"
import "hash/crc64"
import "hash/maphash"
import "fmt"
func maphashDemo() {
var h maphash.Hash
// Add a string to the hash, and print the current hash value.
h.WriteString("hello, ")
fmt.Printf("%v\n", h.Sum64())
h.Reset() // seed unchanged, so same value for same string
h.WriteString("hello, ")
fmt.Printf("%v\n", h.Sum64())
}
func crcDemo() {
}
maphashDemo()
crcDemo()
## math
Package rand implements pseudo-random number generators.
**random API**
1
2
3
4
5
6
7
8
9
10
11
- func (r *Rand) Float32() float32 [0, 1)
- func (r *Rand) Int() int
- func (r *Rand) Int31() int32
- func (r *Rand) Int63() int64
- func (r *Rand) Intn(n int) int range [0, n)
- func (r *Rand) Int31n(n int32) int32 [0, n)
- func (r *Rand) Int63n(n int64) int64 \[0, n)
- func (r *Rand) Uint32() uint32
- func (r *Rand) Uint64() uint64
1
2
3
4
5
6
7
8
9
10
import "math/rand"
import "fmt"
func randDemo() {
// set seed
r := rand.New(rand.NewSource(99))
fmt.Println(r.Float32(), r.Int(), r.Intn(100), r.Uint32())
}
randDemo()
0.2635776 5864379541603903257 90 2699839765
## crypto
Package, crypto, aes, des, rsa, sha1, sha256, hmac, md5
## file/IO ops
There are many ways to read and write IO in golang. At present, I know `IO library, OS library, ioutil library, bufio library, bytes library and so on`, which one to choose? which library should be used in what scenario?
- The OS library mainly deals with the operating system, so file operations are basically linked with the OS library, such as creating a file, deleting a file, change file mode, creating dir etc. This library is often used with ioutil library, bufio library, etc
- *os.File is a type that implements io.Reader, and io.Writer (among others) which streams bytes to or from a file on disk
It is useful if you don't want to read the whole file into memory, It has the downside of being a lower level construct, meaning data must often be processed in loops (with error checks on each iteration), and that it must be manually managed (via Close())
- io library belongs to the bottom interface definition library.
- its function is to `define some basic interfaces and some basic constants,` and to explain the functions of these interfaces. The common interfaces are reader, writer, etc. Generally, `this library is only used to call its constants, such as io.EOF`.
- The ioutil library is included in the IO directory. It is mainly used as a toolkit. There are some practical functions, such as readall (read data from a source), readfile (read file content), WriteFile (write data to a file), readdir (get directory), it's easy to use, like readfile, `it does some operation automatically which we should do by ourself if use os.File`
- It automatically allocates a byte slice of the correct size (no need to Read + append in a loop)
- It automatically closes the file
- It returns the first error that prevented it from working (so you only need a single error check)
- bufio provides wrapper types for io.Reader and io.Writer that buffer the input / output to improve efficiency.
- If you are reading a file in one or a few large steps, you probably don't need it either
- buffered input and output add some extra concerns
- bufio.Scanner is a nice utility type to efficiently read independent lines of text from an io.Reader
- bytes provides helper functions and types for interacting with byte slices ([]byte)
- `bytes.Reader turns a []byte into a io.Reader (as well as an io.Seeker to rewind)`
- `bytes.Buffer uses []bytes to implement a reader/writer, it is useful when you want to use code that takes an io.Writer, and store the results in memory for use later`
- bufio vs bytes.Buffer: both of them provide a layer of caching function. The main difference between them is that `bufio is for file to memory caching, wrap other Reader/Writer`, while `bytes.Buffer is for memory to memory caching`.
**Suggestion**
- **file operation, create/delete/chmod use` os library`**
- **small file, load at once, use `ioutil`**
- **large file, `bufio` support read line by line, or read word by word etc**
- **control read size of file by yourself, read many times, `os.File`**
- **In memory reader/writer `bytes.Buffer`**
When Read encounters an error or end-of-file condition after successfully reading n > 0 bytes, it returns the number of bytes read. It may return the (non-nil) error from the same call or return the error (and n == 0) from a subsequent call. An instance of this general case is that **a Reader returning a non-zero number of bytes at the end of the input stream may return either err == EOF or err == nil. The next Read should return 0, EOF**.
Callers should always process the n > 0 bytes returned before considering the error err. Doing so correctly handles I/O errors that happen after reading some bytes and also both of the allowed EOF behaviors.
[IO-Cookbook](https://jesseduffield.com/Golang-IO-Cookbook/)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
src:
- bufio
- bufio.go
- bytes
- buffer.go
- reader.go
- io
- ioutil
- ioutil.go
- io.go
- os
- file.go
- strings
- reader.go
io/ioutil was a poorly defined collection of helpers, you should use os.xxx if avaiable.
### os
standard package `os` provides basic operations file system while File provides read/write operations.
- func Chdir(dir string) error
- func Chmod(name string, mode FileMode) error
- func Chown(name string, uid, gid int) error
- func Stat(name string) (FileInfo, error)
- func IsExist(err error) bool
- func IsNotExist(err error) bool
- func ReadDir(name string) ([]DirEntry, error)
- func Mkdir(name string, perm FileMode) error
- func MkdirAll(path string, perm FileMode) error
- func MkdirTemp(dir, pattern string) (string, error)
- func Remove(name string) error
- func RemoveAll(path string) error
- func Rename(oldpath, newpath string) error
- func ReadFile(name string) ([]byte, error) // read all at once
- func Create(name string) (*File, error)
- func Open(name string) (*File, error)
- func OpenFile(name string, flag int, perm FileMode) (*File, error)
- func (f *File) Close() error
- func (f *File) Read(b []byte) (n int, err error) // read size of slice from file
- func (f *File) ReadAt(b []byte, off int64) (n int, err error)
- func (f *File) Write(b []byte) (n int, err error)
- func (f *File) WriteAt(b []byte, off int64) (n int, err error)
- func (f *File) WriteString(s string) (n int, err error)
- func (f *File) ReadDir(n int) ([]DirEntry, error)
- func (f *File) Sync() error
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
package main
import (
"fmt"
"os"
)
func FileMakePath(path string) error {
if stat, err := os.Stat(path); os.IsExist(err) {
if stat.IsDir() {
return nil
}
return fmt.Errorf("[util] %s exists, but not dir", path)
}
// create if not exists
if err := os.MkdirAll(path, 0777); err != nil {
return err
}
return nil
}
func main() {
info, err := os.Stat("/tmp/test")
if err != nil {
if os.IsNotExist(err) {
fmt.Println("/tmp/test not found, creating it")
_, err := os.Create("/tmp/test")
if err != nil {
fmt.Printf("create failed: %v\n", err)
} else {
fmt.Println("created")
os.Chmod("/tmp/test", 0777)
}
} else {
fmt.Println(err)
}
} else {
fmt.Printf("stats of /tmp/test: %v\n", info)
}
// If the file doesn't exist, create it, or append to the file
file, err := os.OpenFile("/tmp/test", os.O_CREATE|os.O_WRONLY, 0644)
if err != nil {
fmt.Println(err)
return
}
// write data to file
file.Write([]byte("ab\n"))
file.WriteString("hello")
file.Close()
data := make([]byte, 100)
file, err = os.Open("/tmp/test")
// read data from file at most 100 bytes!!
_, err = file.Read(data)
if err != nil {
fmt.Println("read error ", err)
file.Close()
return
}
fmt.Printf("file content: \n%s\n", string(data))
file.Close()
if os.Remove("/tmp/test") != nil {
fmt.Println("failed to remove file /tmp/test")
} else {
fmt.Println("removed file /tmp/test")
}
}
main()
/tmp/test not found, creating it
created
file content:
ab
hello
removed file /tmp/test
### ioutil
#### read whole file once
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package main
import (
"fmt"
"strings"
"io/ioutil"
)
func main() {
fmt.Println("write hello to file")
// easy to write and read file !!!
err := ioutil.WriteFile("/tmp/test.txt", []byte("hello \nworld"), 0644)
if err != nil {
fmt.Println(err)
return
}
// read whole file at once, if file is large not good way
file, err := ioutil.ReadFile("/tmp/test.txt")
if err != nil {
fmt.Println(err)
return
}
fmt.Printf("read content: %s", file)
// readall from io.Reader
r := strings.NewReader("hello\nboy\n")
buf, _ := ioutil.ReadAll(r)
fmt.Printf(string(buf))
}
main()
write hello to file
read content: hello
worldhello
boy
### bufio
In some case, **file is large, we want to read line by line, or read until meet delimiter or read word by word**, this what bufio supports, it also provides read any data size but with buffer.
**bufio is a wrapper of another io.Reader/io.Writer, then gives more advanced feature, hence in order to use it, you need an io.Reader firstly, as it wraps io.Reader/io.Writer, hence you should NOT close it with bufio interface, but with io.Reader/io.Writer interface, use interfaces provided by bufio for reading/writing only**
**API**
- `func (b *Reader) Read(p []byte) (n int, err error)`
>Read reads data into p. It returns the number of bytes read into p. The bytes are taken from at most one Read on the underlying Reader, hence n may be less than len(p).
- `func (b *Reader) ReadBytes(delim byte) ([]byte, error)`
>ReadBytes reads until the first occurrence of delim in the input, returning a slice **containing the data up to and including the delimiter**. If ReadBytes encounters an error before finding a delimiter, it returns the data read before the error and the error itself (often io.EOF). ReadBytes returns err != nil if and only if the returned data does not end in delim. For simple uses, a Scanner may be more convenient.
- `func (b *Reader) ReadString(delim byte) (string, error)`
>Same as ReadBytes as it just calls ReadBytes directly, then convert bytes to string
- `func (s *Scanner) Scan() bool`
>returns until the first occurrence of delim in the input(or error, EOF), by default delim is `\n`, or `\r\n`
**NOTE: `\r\n, \n` is returned by `ReadBytes() and ReadString()` which is not true for Scanner.Text(),Scanner.Bytes() which striped**
#### read file line by line
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
package main
import (
"bufio"
"fmt"
"io"
"strings"
)
func main() {
r := strings.NewReader("hello boy\ngirl\n")
// Reader
br := bufio.NewReader(r)
line, err := br.ReadString('\n')
if err != nil {
fmt.Printf("%v", err)
} else {
// line with \n!!!, its count is 10!!!
fmt.Printf("%v: %d\n", line, len([]rune(line)))
}
line, err = br.ReadString('\n')
if err != nil {
if err == io.EOF {
fmt.Printf("%v", line)
} else {
fmt.Printf("%v", err)
}
} else {
fmt.Printf("%v: %d\n", line, len([]rune(line)))
}
fmt.Println("use scanner")
// Scanner to read line by line
// return to start position
r.Seek(0, 0)
scanner := bufio.NewScanner(r)
// read word by word: scanner.Split(bufio.ScanWords)
for scanner.Scan() {// returns until \n!!!
//scaner.Text() has stripped line, no \n
fmt.Println(scanner.Text(), len([]rune(scanner.Text())))
fmt.Println(string(scanner.Bytes()), len(scanner.Bytes()))
}
if err := scanner.Err(); err != nil {
fmt.Println(err)
}
}
main()
hello boy
: 10
girl
: 5
use scanner
hello boy 9
hello boy 9
girl 4
girl 4
### io.Copy and io.Pipe and bytes.Buffer and string.NewReader()
Package io provides basic interfaces to I/O primitives. Its primary job is to wrap existing implementations of such primitives, such as those in package os, into `shared public interfaces that abstract the functionality, plus some other related primitives`.
In most cases, `we did NOT use io library directly, but it provides two convenient ways io.Copy and io.Pipe which is used in most application.`
- `func Copy(dst Writer, src Reader) (written int64, err error)`
>Copy copies from src to dst until either EOF is reached on src or an error occurs. It returns the number of bytes copied and the first error encountered while copying, if any. A successful Copy returns err == nil, not err == EOF. Because Copy is defined to read from src until EOF, it does not treat an EOF from Read as an error to be reported.
If src implements the WriterTo interface, the copy is implemented by calling src.WriteTo(dst). Otherwise, if dst implements the ReaderFrom interface, the copy is implemented by calling dst.ReadFrom(src).
- `func Pipe() (*PipeReader, *PipeWriter)`
>Pipe creates a `synchronous in-memory pipe`. It can be used to connect code expecting an io.Reader with code expecting an io.Writer. Reads and Writes on the pipe are matched one to one except when multiple Reads are needed to consume a single Write. That is, **each Write to the PipeWriter blocks until it has satisfied one or more Reads from the PipeReader that fully consume the written data**. The data is copied directly from the Write to the corresponding Read (or Reads); there is no internal buffering.
**Note**
- pipe.Write() returns only when **error happens or all data is received by reader, otherwise it blocks**
- pipe.Read() returns data received and tell Writer how many it receives, so that writer can write immediately after get the notification
**Cases**
- io.Copy: Get data(bytes) from reader, without any change, Write to writer **(no user involved)**, this what io.Copy mostly used, reader and writer can anyone like file, string, in memory etc!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
package main
import (
"bytes"
"io"
"os"
"strings"
)
func main() {
r := strings.NewReader("hello boy\ngirl\n")
// copy from reader to writer
// support any reader and any writer
io.Copy(os.Stdout, r)
var buffer *bytes.Buffer
buffer = bytes.NewBufferString("hello boy\ngirl\n")
io.Copy(os.Stdout, buffer)
}
- io.Pipe() same as io.Copy, but more limitation and more efficient, as reader and writer are bound from beginning and they are in memory, **need user call write() and read() API**.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
package main
import (
"fmt"
"io"
"strings"
"time"
)
func main() {
preader, pwriter := io.Pipe()
go func() {
reader := strings.NewReader("ab")
fmt.Println("writer writes data and blocks as reader is not ready")
io.Copy(pwriter, reader)
fmt.Println("writer waked up after data is read")
}()
// Read blocks until writer write data or writer close/error
buf := make([]byte, 60)
fmt.Println("reader sleep 1 seconds before reading")
time.Sleep(time.Second * 1)
c, err := preader.Read(buf)
if err != nil {
fmt.Println("error reading")
} else {
buf[2] = 'c'
//fmt.Println(string(buf))
fmt.Println(string(buf[:c]))
}
}
main()
reader sleep 1 seconds before reading
writer writes data and blocks as reader is not ready
writer waked up after data is read
ab
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
package main
// Importing fmt, io, and bytes
import (
"fmt"
"io"
)
// Calling main
func main() {
// Calling Pipe method
pipeReader, pipeWriter := io.Pipe()
// Using Fprint in go function to write
// data to the file
go func() {
// block here until reader read it all or read call Close()
n, err := fmt.Fprint(pipeWriter, "Geeks\n")
// the print may be printed before or after last rcv!!!
fmt.Printf("pipeWriter returns %v bytes is written err: %v\n", n, err)
// Using Close method to close write
pipeWriter.Close()
}()
buf := make([]byte, 2)
for {
n, err := io.ReadFull(pipeReader, buf)
if err == io.EOF {
break
} else {
fmt.Printf("rcv: %v bytes: %q\n", n, string(buf))
}
}
}
**Possible output**
1
2
3
4
5
6
7
8
9
10
rcv: 2 bytes: "Ge"
rcv: 2 bytes: "ek"
rcv: 2 bytes: "s\n"
pipeWriter returns 6 bytes is written err: <nil>
rcv: 2 bytes: "Ge"
rcv: 2 bytes: "ek"
pipeWriter returns 6 bytes is written err: <nil>
rcv: 2 bytes: "s\n"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import (
"fmt"
"io"
"time"
)
// Calling main
func main() {
// Calling Pipe method
pipeReader, pipeWriter := io.Pipe()
// Using Fprint in go function to write
// data to the file
go func() {
// block here until reader read it all or read call Close()
n, err := fmt.Fprint(pipeWriter, "Geeks\n")
fmt.Printf("pipeWriter returns: %v bytes is written err: %v\n", n, err)
// Using Close method to close write
pipeWriter.Close()
}()
// data into buffer
fmt.Println("starts to read")
buf := make([]byte, 2)
for {
n, err := io.ReadFull(pipeReader, buf)
if err == io.EOF {
break
} else {
fmt.Printf("rcv: %v bytes: %q\n", n, string(buf))
pipeReader.Close()
// sleep a while for writer to quit first
time.Sleep(time.Second * 2)
break
}
}
}
main()
starts to read
rcv: 2 bytes: "Ge"
pipeWriter returns: 2 bytes is written err: io: read/write on closed pipe
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
package main
import (
"bytes"
"fmt"
"io"
"log"
"os"
"strings"
)
func main() {
r := strings.NewReader("some io.Reader stream to be read\n")
if _, err := io.Copy(os.Stdout, r); err != nil {
// copy from reder to os.Stdout(console)
log.Fatal(err)
}
// an new memory buffer.
buf := make([]byte, 60)
buffer := bytes.NewBuffer(buf)
// after Copy, reader reach to EOF, we we should reset it to read data again
r.Seek(0, 0)
// read from reader to buffer!!!
buffer.ReadFrom(r)
fmt.Printf("%s", buffer.String())
fmt.Printf("%q", buffer.String())
}
main()
some io.Reader stream to be read
some io.Reader stream to be read
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00some io.Reader stream to be read\n"
### list all files(file,dir) under a dir
- os.ReadDir (return all)
- os.File.ReadDir(can limit return entries)
- ioutil.ReadDir(less efficient than os.ReadDir
- filepath.Glob(support patterns)
- filepath.Walk(support recursive sub-dirs, above does not support this)
## signal
**[signal wiki page](https://en.wikipedia.org/wiki/Signal_(IPC))**
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
)
func main() {
c := make(chan os.Signal, 1)
// os.Interrupt<---->syscall.SIGINT (Ctrl+C)
// os.Kill <---->syscall.SIGKILL
signal.Notify(c, os.Interrupt)
signal.Notify(c, os.Kill)
signal.Notify(c, syscall.SIGQUIT)
signal.Notify(c, syscall.SIGTERM)
select {
case s := <-c:
fmt.Println("sig: ", s)
}
}
## random
Random numbers are generated by a Source. Top-level functions, such as and Int, use a default shared Source that produces a deterministic sequence of values each time a program is run. Use the Seed function to initialize the default Source if different behavior is required for each run. The default Source is safe for concurrent use by multiple goroutines, but Sources created by NewSource are not.
This package's outputs might be easily predictable regardless of how it's seeded. For random numbers suitable for security-sensitive work, see the `crypto/rand` package.
- Int/Int31/Int63: generate random number without range
- Intn/Int31n/Int63n: generate random number from [0, n)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
rand.Seed(time.Now().UnixNano())
fmt.Println(rand.Int(), rand.Intn(10))
fmt.Println(rand.Int31(), rand.Int31n(10))
fmt.Println(rand.Int63(), rand.Int63n(10))
// generate bunch of numbers
buf := make([]byte, 6)
rand.Read(buf)
fmt.Println(buf)
}
main()
5656737410240953005 4
670732630 8
846728672197744499 9
[40 95 241 197 58 113]
## template
There are two packages operating with templates `text/template and html/template`. Both provide the same interface, however the html/template package is used to generate HTML output safe against code injection.
Templates are executed by applying them to a `data structure`. Annotations in the template refer to elements of the data structure (typically a field of a struct or a key in a map) to control execution and derive values to be displayed. `Execution of the template walks the structure and sets the cursor, represented by a period '.' and called "dot", to the value at the current location in the structure as execution proceeds.`, **data structure is represented by a period '.'**
To obtain data from a struct, you can use the `{{ .FieldName }}` action, which will replace it with FieldName value of given struct, on parse time.
There is also the {{ . }} action that you can use to refer to a value of non-struct types.
Templates are provided to the appropriate functions either as string or as “raw string”. Actions represents the data evaluations, functions or control loops. They are delimited by {{ }}. Other, non delimited parts are left untouched.
Here is the list of actions. “Arguments” and “pipelines” are evaluations of data, defined in detail in the corresponding sections that follow.
1 | {{/* a comment */}} |
Basics
1 | // template from a file |
Rules to write template, refer to template format and built-in functions, template examples, extra functions provided by sprig
1 | package main |
raw string
wool
17
NO Cool in field
17
non-standard
uuid
uuid.UUID is new type(alias) [16]byte
1 | package main |
string to uuid bytes
1 | uid, _:= uuid.Parse("b1762c24-48ff-4f67-a66c-e3aeb66051f0") |
bytes to uuid string
1 | uid, _:= uuid.FromBytes(bytes) |
log
Besides the standard log package, there are lots of log library for Go, here are some popular ones.
1 | package main |
- logrus–>structured logger, completely API compatible with the standard library logger
- zap–>structured, leveled logging in Go, high performance
- glog–>simple, stable, standard lib provided by Go
- oklog—->no updates years, old
- seelog–>no updates years, old
- zerolog –>json output
Suggestion:
- For simple usage, use glog
- Structured, use logrus
- Need high performance, zap is best choice.
glog
format when writing logs <header>] <message>, header has below format.Lmmdd hh:mm:ss.uuuuuu threadid file:line
- L: log level, I(INFO), W(WARNING), E(ERROR), F(FATAL))
- mmdd hh:mm:ss.uuuuuu time of log
- threadid: thread id
- file:line: file trigger the log
Log format ExampleI0715 13:28:17.923715 31920 main.go:14] hello message
API
- glog.Flush()
- glog.Info()/glog.Infof()/glog.Infoln()
- glog.Warning()/glog.Warningf()/glog.Warningln()
- glog.Error()/glog.Errorf()/glog.Errorln()
- glog.Fatal()/glog.Fatalf()/glog.Fatalln(), note os.Exit() when Fatalx() called.
NOTE
glog.Infof(), glog.Errorf(), glog.Warningf() will auto added
\nat last if user not setglog saves different log level to different files, but low log file contains high log as well, say INFO log files has ERROR log as well!!!
glog.Info/Warning/Error/Fatal always writes log to file, no switch to turn it on/off
use glog.V() and pass -v flag to control whether or not to write log to Info file, as V only provides
Infof(), that means, it’s INFO log!!!, so do NOT use it for error, warning, trace logs!!!By default, glog saves logs to /tmp,
change it to your path with -log_dirBy default, glog does not print log to std, change it
to stdio instead of file with -logtostderrNeed both std and file,
use -alsologtostderr as well as -log_dirmust put it at main(): flag.Parse()
1 | # log to /var/log dir, make sure it exists |
Sample code
1 | package main |
V style
1 | package main |
logrus
log Format$level[0000] message $field=$value $field=$valueINFO[0000] A walrus appears animal=walrus
API
- log.Trace(“Something very low level.”)
- log.Debug(“Useful debugging information.”)
- log.Info(“Something noteworthy happened!”)
- log.Warn(“You should probably take a look at this.”)
- log.Error(“Something failed but I’m not quitting.”)
- log.Fatal(“Bye.”) // Calls os.Exit(1) after logging
- log.Panic(“I’m bailing.”) // Calls panic() after logging
Sample code
1 | package main |
gopsutil
In most monitor system, we need to get some info about the system, like CPU, memory, disk, net, process etc, gopsutil provides better API to support these, you do NOT need to deal with OS related files or API, gopsutil handles this for you, its supports get info about below aspects.
- cpu
- disk
- docker
- host
- load
- mem
- net
- process
- winservices
1 | package main |
More details, please refer to gopsutil
file ops
As os package provides basic function to operation file system, it still have more work for user to do,that’s why afero comes in, it gives a lot of very powerful possibilities.
afero
Afero is a filesystem framework providing a simple, uniform and universal API interacting with any filesystem, as an abstraction layer providing interfaces, types and methods, it provides significant improvements over using the os package alone, most notably the ability to create mock and testing filesystems without relying on the disk.
It is suitable for use in any situation where you would consider using the OS package as it provides an additional abstraction that makes it easy to use a memory backed file system during testing. It also adds support for the http filesystem for full interoperability.
File System Methods Available:
1 | Chmod(name string, mode os.FileMode) : error |
File Interfaces and Methods Available:
1 | io.Closer |
Utilities
1 | DirExists(path string) (bool, error) |
Declare a backend
The backend can be In memory, native OS system, readonly etc
1 | import "github.com/spf13/afero" |
CLI
There are lots of pkgs to develop CLI, here only list some of them.
- flag: simple, standard lib, not support subcommand
- pflag: implementing POSIX/GNU-style –flags
- go-flags: This library provides similar functionality to the builtin flag library of go, but provides much more functionality and nicer formatting.
- urfave/cli: popular one
- spf13/cobra: more powerful, used by k8s, docker etc
Suggestion
- very simple use, no subcommand needed, less options, use flag
- simple use, lots of options, use go-flags
- complex command line cobra
flag
1 | package main |
go-flags
Package flags provides an extensive command line option parser. The flags package is similar in functionality to the go builtin flag package but provides more options and uses reflection to provide a convenient and succinct way of specifying command line options.
Supported features:
- Options with short names (-v)
- Options with long names (–verbose)
- Options with and without arguments (bool v.s. other type)
- Options with
optional arguments and default values - Multiple option groups each containing a set of options
- Generate and print well-formatted help message
- Passing remaining command line arguments after – (optional)
- Ignoring unknown command line options (optional)
- Supports -I/usr/include -I=/usr/include -I /usr/include option argument specification
- Supports multiple short options -aux
- Supports all primitive go types (string, int{8..64}, uint{8..64}, float)
- Supports same option multiple times (can store in slice or last option counts)
- Supports maps
- Supports function callbacks
- Supports namespaces for (nested) option groups
1 | package main |
spf13/cobra
Cobra is a library providing a simple interface to create powerful modern CLI interfaces similar to git & go tools.
Cobra provides:
- Easy subcommand-based CLIs: app server, app fetch, etc.
- Fully POSIX-compliant flags (including short & long versions)
- Nested subcommands
- Global, local and cascading flags
- Easy generation of applications & commands with cobra init appname & cobra add cmdname
- Intelligent suggestions (app srver… did you mean app server?)
- Automatic help generation for commands and flags
- Automatic help flag recognition of -h, –help, etc.
- Automatically generated shell autocomplete for your application (bash, zsh, fish, powershell)
- Automatically generated man pages for your application
Cobra is built on a structure of commands, arguments & flags.
Commands represent actions, Args are things and Flags are modifiers for those actions.like this git clone URL --bare
How to write CLI by cobra
Go cron scheduling
go cron is a Golang job scheduling package which lets you run Go functions periodically at pre-determined interval using a simple, human-friendly syntax.
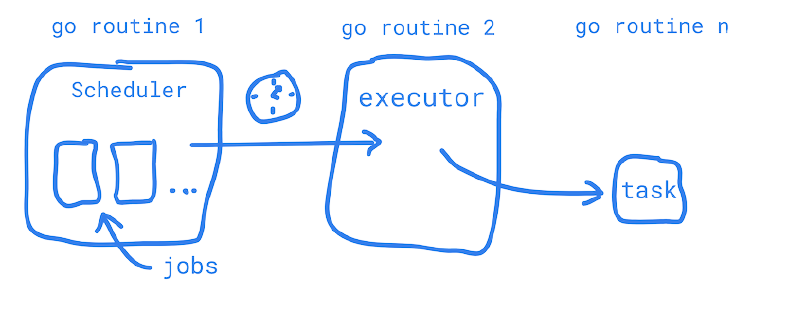
- Scheduler: The scheduler tracks all the jobs assigned to it and makes sure they are passed to the executor when ready to be run. The scheduler is able to manage overall aspects of job behavior like limiting how many jobs are running at one time.
- Job: The job is simply aware of the task (go function) it’s provided and is therefore only able to perform actions related to that task like preventing itself from overruning a previous task that is taking a long time.
- Executor: The executor, as it’s name suggests, is simply responsible for calling the task (go function) that the job hands to it when sent by the scheduler.
Tags
Jobs may have arbitrary tags added which can be useful when tracking many jobs. The scheduler supports both enforcing tags to be unique and when not unique, running all jobs with a given tag.
Interval supports
- milliseconds
- seconds
- minutes
- hours
- days
- weeks
- months
1 | s := gocron.NewScheduler(time.UTC) |
Example
1 | s := gocron.NewScheduler(time.UTC) |
More examples, refer to cron example
Note:
Q: I’ve removed my job from the scheduler, but how can I stop a long-running job that has already been triggered?
A: We recommend using a means of canceling your job, e.g. a context.WithCancel().
HTTP Server
Restful API server
Here we only list pure restful api server package, which is small, fast.
Let’s focus on mux which is powerful and used in many production
gorilla/mux
Paths can have variables. They are defined using the format {name} or {name:pattern}. If a regular expression pattern is not defined, the matched variable will be anything until the next slash.
1 | r := mux.NewRouter() |
Routes can also be restricted
1 | r := mux.NewRouter() |
Group several routes that share the same requirements
1 | r := mux.NewRouter() |
Graceful shutdown
1 | package main |
show all routes call walk of the router
1 | r.Walk(func(route *mux.Route, router *mux.Router, ancestors []*mux.Route) error { |
NOTE
- Routes are tested in the order they were added to the router. If two routes match, the first one wins
- each handler must declare like this
func HandlerXXX(w http.ResponseWriter, r *http.Request) {}
1 | package main |
yaml vs json vs toml
TOML shares traits with other file formats used for application configuration and data serialization, such as YAML and JSON. TOML and JSON both are simple and use ubiquitous data types, making them easy to code for or parse with machines. TOML and YAML both emphasize human readability features, like comments that make it easier to understand the purpose of a given line. TOML differs in combining these, allowing comments (unlike JSON) but preserving simplicity (unlike YAML).
spec
Golang support
- Yaml
- BurntSushi/toml
This Go package provides a reflection interface similar to Go’s standard library json and xml packages. This package also supports the encoding.TextUnmarshaler and encoding.TextMarshaler interfaces so that you can define custom data representations, it supports tag as well like json type b struct{Port string
toml:"port,omitempty"} - Viper
- Find, load, and unmarshal a configuration file in JSON, TOML, YAML, HCL, INI, envfile or Java properties formats.
- Provide a mechanism to set default values for your different configuration options.
- Provide a mechanism to set override values for options specified through command line flags.
- Provide an alias system to easily rename parameters without breaking existing code.
- Make it easy to tell the difference between when a user has provided a command line or config file which is the same as the default.
toml decode
1 | var config tomlConfig |
1 | # This is a TOML document. Boom. |
1 | package main |
1 | package main |
decode from encoded buffer(toml to struct): {Age:10}
toml encode
1 | // dst can be bytes.Buffer or File who implements io.Writer |
1 | package main |
2022/07/01 17:23:30 encoded first buffer toml format: Age = 13
Cats = ["one", "two", "three"]
Pi = 3.145
Perfection = [11, 2, 3, 4]
DOB = 2022-07-01T17:23:30.172328016+08:00
Ipaddress = "192.168.59.254"
2022/07/01 17:23:30 decode from encoded buffer(toml to struct): {Age:13 Cats:[one two three] Pi:3.145 Perfection:[11 2 3 4] DOB:2022-07-01 17:23:30.172328016 +0800 CST Ipaddress:192.168.59.254}
2022/07/01 17:23:30 encoded second buffer toml format: Age = 13
Cats = ["one", "two", "three"]
Pi = 3.145
Perfection = [11, 2, 3, 4]
DOB = 2022-07-01T17:23:30.172328016+08:00
Ipaddress = "192.168.59.254"
bit
Only support 64 bits [0, 63].
1 | package main |
1 | bm1(0 as the first bit): 0111 |
encoding(protobuffer)
A very simple “address book” application that can read and write people’s contact details to and from a file. Each person in the address book has a name, an ID, an email address, and a contact phone number.
How do you serialize and retrieve structured data like this? There are a few ways to solve this problem:
- Use
gobs to serialize Go data structures. This is a good solution in a Go-specific environment, but it doesn’t work well if you need to share data with applications written for other platforms. - You can
invent an ad-hoc way to encode the data items into a single stringsuch as encoding 4 ints as “12:3:-23:67”. This is a simple and flexible approach, although it does require writing one-off encoding and parsing code, and the parsing imposes a small run-time cost. This works best for encoding very simple data. Serialize the data to XML(or json). This approach can be very attractive since XML is (sort of) human readable and there are binding libraries for lots of languages. This can be a good choice if you want to share data with other applications/projects. However, XML is notoriously space intensive, and encoding/decoding it can impose a huge performance penalty on applications. Also, navigating an XML DOM tree is considerably more complicated than navigating simple fields in a class normally would be.
Protocol buffers are the flexible, efficient, automated solution to solve exactly this problem. With protocol buffers, you write a .proto description of the data structure you wish to store. From that, the protocol buffer compiler creates a class that implements automatic encoding and parsing of the protocol buffer data with an efficient binary format. The generated class provides getters and setters for the fields that make up a protocol buffer and takes care of the details of reading and writing the protocol buffer as a unit. Importantly, the protocol buffer format supports the idea of extending the format over time in such a way that the code can still read data encoded with the old format.
Rules for compatibility
Sooner or later after you release the code that uses your protocol buffer, you will undoubtedly want to “improve” the protocol buffer’s definition. If you want your new buffers to be backwards-compatible, and your old buffers to be forward-compatible and you almost certainly do want this then there are some rules you need to follow. In the new version of the protocol buffer:
- you must not change the tag numbers of any existing fields.
- you may delete fields.
- you may add new fields but you must use fresh tag numbers (i.e. tag numbers that were never used in this protocol buffer, not even by deleted fields).
If you follow these rules, old code will happily read new messages and simply ignore any new fields. To the old code, singular fields that were deleted will simply have their default value, and deleted repeated fields will be empty. New code will also transparently read old messages.
However, keep in mind that new fields will not be present in old messages, so you will need to do something reasonable with the default value. A type-specific default value is used: for strings, the default value is the empty string. For booleans, the default value is false. For numeric types, the default value is zero.
style
style guide gives suggestion how to write xx.proto file when define message and rpc, here is a summary from that.
All files should be ordered in the following manner:
- License header (if applicable)
- File overview
- Syntax(proto2 or proto3)
- Package(used by proto to import message defined in other package)
- Imports (sorted)(imports other protos)
- File options(like option go_package = “github.com/xvrzhao/pb-demo/proto/article”;)
- Everything else
1
2
3
4syntax="proto3";
package hello;
import "store/name.proto"
option go_package = "github.com/jason/hello"
Message and field names
Use CamelCase (with an initial capital) for message names for example, SongServerRequest. Use underscore_separated_names for field names (including oneof field and extension names) for example, song_name
1 | message SongServerRequest { |
Repeated fields
Use pluralized names for repeated fields.
1 | repeated string keys = 1; |
Enums
Use CamelCase (with an initial capital) for enum type names and CAPITALS_WITH_UNDERSCORES for value names:
1 | enum FooBar { |
Services
Use CamelCase (with an initial capital) for both the service name and any RPC method names:
1 | service FooService { |
proto3
Default values:
- For strings, the default value is the empty string.
- For bytes, the default value is empty bytes.
- For bools, the default value is false.
- For numeric types, the default value is zero.
- For enums, the default value is the first defined enum value, which must be 0.
- For message fields, the field is not set. Its exact value is language-dependent. See the generated code guide for details.
go references
build proto3 of go
In order to generate go code, you must have protoc and go plugins installed, here are steps to install them all.
Prerequisite
1 | $ wget -O ./protoc-3.15.8-linux-x86_64.zip https://github.com/protocolbuffers/protobuf/releases/download/v3.15.8/protoc-3.15.8-linux-x86_64.zip |
gogo/protobuf
gogo/protobuf is a fork of golang/protobuf with extra code generation features, it provides several plugins for go code generate, pick the right one for use
- protoc-gen-gofast(speed than protoc-gen-go)
- protoc-gen-gogofast (same as gofast, but imports gogoprotobuf)
- protoc-gen-gogofaster (same as gogofast, without XXX_unrecognized, less pointer fields)
- protoc-gen-gogoslick (same as gogofaster, but with generated string, gostring and equal methods)
- protoc-gen-gogo (Most Speed and most customization)
1 | # basic way |
In order to generate Go code, the Go package’s import path must be provided for every .proto file). There are two ways to specify the Go import path:
by declaring it within the .proto file
option go_package = “example.com/project/protos/fizz”;’by declaring it on the command line when invoking protoc, by passing one or more
M${PROTO_FILE}=${GO_IMPORT_PATH}
$protoc –go_opt=Mprotos/buzz.proto=example.com/project/protos/fizz protos/buzz.proto`
compile proto
use cases for code generation of Go
1 | # --go_out=. generate go code under this directory |
Most used one: put your source at $GOPATH/src/github.com $ protoc --go_out=$GOPATH/src/ --go_opt=paths=import --go-grpc_out=$GOPATH/src/ --go-grpc_opt=paths=import protocols/greet.proto$ protoc --gogo_out=. --gogo_opt=paths=source_relative --go-grpc_out=$GOPATH/src/ --go-grpc_opt=paths=import protocols/greet.proto
Most used one for testing$ protoc --go_out=. --go_opt=paths=source_relative protocols/greet.proto$ protoc --gogo_out=. --gogo_opt=paths=source_relative protocols/greet.proto
1 | (base) [root@localhost hello]# pwd |
generated go code
greet.proto
1 | syntax = "proto3"; |
For nested message, generated go code with its parent as prefix like type Person_PhoneNumber struct
If a field value isn't set, a default value is used: zero for numeric types, the empty string for strings, false for bools. For embedded messages, the default value is always the “default instance” or “prototype” of the message, which has none of its fields set. Calling the accessor to get the value of a field which has not been explicitly set always returns that field’s default value.
If a field is repeated, the field may be repeated any number of times (including zero). The order of the repeated values will be preserved in the protocol buffer. Think of repeated fields as dynamically sized arrays.
There is no correlation between the Go import path and the package specifier in the .proto file. The latter is only relevant to the protobuf namespace, while the former is only relevant to the Go namespace. Also, there is no correlation between the Go import path and the .proto import path.
The generated Go field names always use camel-case naming, even if the field name in the .proto file uses lower-case with underscores (as it should). Thus, the proto field foo_bar_baz becomes FooBarBaz in Go.
types mapping
| .proto Type | Notes | Go Type |
|---|---|---|
| double | float64 | |
| float | float32 | |
| int32 | Uses variable-length encoding. Inefficient for encoding negative numbers if your field is likely to have negative values, use sint32 instead. | int32 |
| int64 | Uses variable-length encoding. Inefficient for encoding negative numbers if your field is likely to have negative values, use sint64 instead. | int64 |
| uint32 | Uses variable-length encoding. | uint32 |
| uint64 | Uses variable-length encoding. | uint64 |
| sint32 | Uses variable-length encoding. Signed int value. These more efficiently encode negative numbers than regular int32s. | int32 |
| sint64 | Uses variable-length encoding. Signed int value. These more efficiently encode negative numbers than regular int64s. | int64 |
| fixed32 | Always four bytes. More efficient than uint32 if values are often greater than 2^28. | uint32 |
| fixed64 | Always eight bytes. More efficient than uint64 if values are often greater than 2^56. | uint64 |
| sfixed32 | Always four bytes. | int32 |
| sfixed64 | Always eight bytes. | int64 |
| bool | bool | |
| string | A string must always contain UTF-8 encoded or 7-bit ASCII text, and cannot be longer than 2^32. | string |
| bytes | May contain any arbitrary sequence of bytes no longer than 2^32. | []byte |
singular message field
1 | message Baz { |
=>>
1 | type Baz struct { |
Repeated Fields
1 | message Baz { |
=>
1 | type Baz struct { |
Map Fields
1 | message Bar {} |
=>
1 | type Baz struct { |
Enum
1 | message SearchRequest { |
=>
1 | type SearchRequest_Corpus int32 |
use generated code
1 | p := pb.Person{ |
pty
By default, Unix-style tty (i.e. console) drivers will take input in "cooked mode". In this mode, it provides a certain amount of command-line editing. The user can type in a line of input, possibly deleting and retyping some of it (but that doesn’t always work) and the program won't see it until the user hits enter.
In contrast, raw mode sets up the TTY driver to pass every character to the program as it is typed. Programs are started in cooked mode by default and need to enable raw mode. that means in raw mode, ctrl+c, ctrl+\ passed in as well, signal hanler is not called!!!, but in cooked mode, it’s handler is called, hence program exits!!!
Here is example how to enable raw mode in C terminal in C which calls ioctl to do this.
go package
Pty is a Go package for using unix pseudo-terminals.go get github.com/creack/pty
shell
run bash in pty to create a new terminal
1 | package main |
1 | package main |
foo
bar
baz
FAQ
use io.pipe or channel?
It depends on the data that will be transmitted, if data is stream, use io.Pipe, if data is fixed type, use channel, as it’s like datagram!!