go-advanced
Advanced
struct
tags
1 | package main |
Rules for writing tag
whitespace, double quote ", colon :are special in tags.Tag
keys must not containspace (Unicode value 32), quote"(Unicode value 34) and:colon (Unicode value 58) characters.To form a valid key-value pair, no space characters are allowed to follow the colon in the supposed key-value pair. So
optional: "yes"doesn’t form key-value pairs.different key-value pairs are separated by whitespace
space characters in tag values are important. So
json:"author, omitempty",json:" author,omitempty"andjson:"author,omitempty"are different from each other.each struct field
tag should present as a single lineto be wholly meaningful.
Exported struct
If a struct type starts with a capital letter, then it is an exported type and it can be accessed from other packages. Similar the fields of a struct start with caps, they can be accessed from other packages.
Structs Equality
Structs are value types and are comparable if each of their fields are comparable. Two struct variables are considered equal if their corresponding fields(field with same name) are equal.
anonymous fields
It is possible to create structs with fields that contain only a type without the field name. These kinds of fields are called anonymous fields. Even though anonymous fields do not have an explicit name, by default the name of an anonymous field is the name of its type.
1 | type Person struct { |
Person struct has 2 fields with name string and int!!!
1 | package main |
Promoted fields
Fields that belong to an anonymous field which is also a struct are called promoted fields since they can be accessed as if they belong to the struct which holds the anonymous struct. promoted fields can be functions as well!!!
1 | package main |
class
There is no class in Go, but you can bind functions with struct, hence it behaves like a class.func (p Person) speak() string {} The receiver appears in its own argument list between the func keyword and the method name.
You can only declare a method with a receiver whose type is defined in the same package as the method. You cannot declare a method with a receiver whose type is defined in another package
Value receiver makes a copy of the type and pass it to the function. The function stack now holds an equal object but at a different location on memory. That means any changes done on the passed object will remain local to the method. The original object will remain unchanged.Pointer receiver passes the address of a type to the function. The function stack has a reference to the original object. So any modifications on the passed object will modify the original object.
If you want to change the state of the receiver in a method, manipulating the value of it, use a pointer receiver. It’s not possible with a value receiver, which copies by value. Any modification to a value receiver is local to that copy. If you don’t need to manipulate the receiver value, use a value receiver(pointer receiver can be used as well).
The Pointer receiver avoids copying the value on each method call. This can be more efficient if the receiver is a large struct.
Value receivers are concurrency safe, while pointer receivers are not concurrency safe. Hence a programmer needs to take care of it.
RULES for receivers
- Try to use same receiver type for all your methods as much as possible, not use both.
- If state modification needed, use pointer receiver if not use value receiver(but can use pointer receive as well, good case for large struct).
Specific class(not interface) method supports
- call pointer receiver on non-pointer object(which is converted to pointer automatically)
- call value receiver on pointer object(which is converted to value object automatically)
Note: Above supports only work for class method, NOT normal function, as normal function with a pointer argument must take a pointer, normal function with a value argument must take a value object not a pointer
1 | type Person struct { |
If you were to call p.speak(), the compiler would automatically change that to (&p).speak(). A similar conversion happens in the other direction if you have a method with a non-pointer receiver and you call it on a pointer, easier to use.
Call method on struct nil pointer, no exception in Go, nil return
1 | import "fmt" |
{1 2}
{2 4}
{1 2}
{2 4}
Interface
Types implicitly satisfy an interface if they implement all required methods defined by that interface.
type T and type *T are different types but *T contains all methods of T, but the other side is not true, even not true you still can call *T method from T object like above(actually implicit conversion happened)
The method set of any other type T consists of all methods declared with receiver type T. The method set of the corresponding pointer type *T is the set of all methods declared with receiver *T or T (that is, it also contains the method set of T).
That means:
If a type
Timplements all methods of an interface using value receiver, then both valueTand pointer of that type*Tcan be used while assigning to that interface variable or while passing to a function which accept an argument as that interface.If a type
Timplements all methods of an interface using pointer receiver, then the only pointer of that type*Tcan be used while assigning to that interface variable or while passing to a function that accepts an argument as that interface.
1 | type Humaner interface { |
interface {} is a special type which has no method, hence all types can be converted to it, it looks like void* in C but it’s not an pointer in Go, an string, int, object, &object can assign to it as well
1 | type Person struct { |
Call method on interface nil pointer, runtime error!!!
More details, refer to inside interface
1 | import ( |
area speak() called by harsh
speak() called by harsh
say() called by harsh
embedding and composing struct
Embedding old way used like C
1 | type User struct { |
Embedding go supported new way
1 | type User struct { |
Composing types
which consists of embedding various types to create other types/interfaces
1 | type ReadWriter interface { |
What I can see from the above definition is that a ReadWriter is an interface which must contain all the functions defined on both Reader and Writer, which are defined elsewhere.
NOTE
- There is no function signature in struct type like we did for C
- If you embed a Interface in struct, that means you declare a Interface variable of the struct!!!
empty struct
Instance of empty struct struct{} in doesn’t occupy any memory. It is of zero byte. it’s used mostly in two cases:
Empty struct is a very good use case in a channel when you only want to use a
channel for notification and not for actually passing in any data. but some one uses bool channel, which is accepted, but empty struct is better choice!!!Implementation of Set data structure. A set is a data structure that holds elements without any particular order. An element only appears once in a set. We use
map[keyType]struct{} for set. struct{} is only just to let us know if an element exists in the set or not.
1 | package main |
set map[a:{}] has 'a': true
set map[a:{}] has 'b': false
1 | package main |
blocked due to no data
after 1s, sent notification, data is ready
wake up after 1s as data is ready
package
A package is a collection of source files in the same directory that are compiled together. Functions, types, variables, and constants defined in one source file are visible to all other source files within the same package.
one package per directory, you can NOT have multiple packages in same directory
create a runnable program
A standalone executable Go program must have package main declaration. If a program is part of the main package, then go build(go install) will create a binary file; which upon execution calls main function of the program, binary file is created only for man package
create a library
If a program is part of a package other than main, then a package archive file is created with go build(go install) command
Package declaration(package xxx at beginning of xx.go) which should be first line of code, file name can be different than package name. When you import a package, package declaration is used to create package reference variable.
Export name(var or method from a package)
A name is exported if it begins with a capital letter, exported means it can be accessed from other package.
package scope
A package scope is a region within a package where a declared variable(even it’s not exported) is accessible from within a package (across all the files in the package).
package init()func init(){} is called by Go when a package is initialized. It does not take any arguments and does not return any value, hence func init(){} is a special function of xx.go file should be only one for a package.
Package alias
When you import a package, Go creates a variable using the package declaration of the package. If you are importing multiple packages with the same name, this will lead to a conflict, use alias to avoid conflict if happens.
1 | import ( |
Publish your packagePublish it on GitHub and you are good to go. If your package is executable, people can use it as a command-line tool else they can import it in a program and use it as a utility module.
inside import statement
1 | import github.com/example/hello |
Above statement essentially means that import package present at directory hello. It doesn’t mean import package hello, it import package under hello/, that also means package name can be different with its directory.
Note
- Go does NOT allow multiple packages at same directory
- import is not recursive, if you have packages under subdirectory, you should import that subdirectory as well.
- dot import: If an explicit period (.) appears instead of a name, all the package’s exported identifiers declared in that package’s package block will be declared in the importing source file’s file block and must be accessed without a qualifier.
import . "fmt", then usePrintln("hello"). but it’s not good way.
searching package
Path of searching packages depends on GO111MODULE is enabled or not but both way check standard library firstly
$GOROOT=/usr/local/go for standard library like fmt, path, cmd, buffio etc.$GOPATH=/home/go for third-party library.
GO111MODULE=on you must have go.mod in your project to build and run!!!
$CURRENT_DIR/vendoris NOT checked anymore!!!$GOROOT/pkg/{arch}/xxx.aprecompiled$GOROOT/srcstandard library for source code$GOPATH/pkg/mod/xxxworkspace for source code
GO111MODULE=off
$CURRENT_DIR/vendorNOT$CURRENT_DIR/vendor/src!!!$GOROOT/pkg/{arch}/xxx.aprecompiled$GOROOT/srcstandard library for source code$GOPATH/pkg/{arch}/xxx.aprecompiled$GOPATH/src/xxxworkspace for source code- Must put your project at $GOPATH/src to make it build
when GO111MODULE=off, go get would fetch all the sources by using their import paths and store them in $GOPATH/src. There was no versioning storing a single git checkout of every package and the ‘master’ branch would represent a stable version of the package.
Go Modules (GO111MODULE=on) were introduced with Go 1.11, Go Modules stores tagged versions with go.mod keeping track of each package’s version
- manually run
GO111MODULE=on go getwould fetch all the sources with tagged versions and saved it at$GOPATH/pkg/mod/ - automatically run
go getwhen you rungo build or go installbased on tagged version from go.mod of each module,you must have go.mod of each module
import package
import statement imports the package under that path, as one package per directory, hence only one package is imported for the path, most of time ,for easy to use, path and package name are same, but the path and package name can be different, if they are different, you need to know both package path and package name, while if they are same, you just need to know one, details refer to package and folder name
go env
1 | check all env of go |
frequently used env
$GOBIN: bin dir of workspace which stores binary for application after go install, default $GOPATH/bin$GOMODCACHE: mod(module) cache source code(xx.go) if mod is not standard library when GO111MODULE is on(mod with version), default $GOPATH/pkg/mod.$GOPATH: working path, hasbin/, src/, mod/, src is used to store download non-standard library(without version)$GOROOT: Standard library of Go
workspace
A workspace is Go’s way to facilitate project management. A workspace, in a nutshell, is a directory on your system where Go looks for source code files, manages dependency packages and build distribution binary files
A workspace can have multiple applications, if different apps refer to same package, they share the same package files at this workspace.
You can have as many workspaces as you want, as long as you keep GOPATH environment variable pointed to the current working workspace directory.
A Go workspace directory must have three sub-directories src, pkg and bin, $GOPATH points to active workspace.
pkg:
- The pkg directory contains Go package objects(get by
go get). They are the compiled versions of the original package source code or source code at pkg/mod for GO111MODULE enabled.
- The pkg directory contains Go package objects(get by
bin:
- The bin directory contains the binary executable files.
These files are created by go install commands. go install command runs go build command internally and then outputs these files to the bin directory
- The bin directory contains the binary executable files.
src:
- The src directory contains Go packages. A package in nutshell is a project directory containing Go source code (.go files). Any packages installed using
GO111MODULE=off go getcommand will reside here as well (and its dependency packages).
- The src directory contains Go packages. A package in nutshell is a project directory containing Go source code (.go files). Any packages installed using
module
Go code is grouped into packages, and packages are grouped into modules, a module can have several related packages but not at same directory, a module is logical groups to track dependencies of all packages in go.mod file, a module only needs one go.mod file at root directory, subdirectory does not need it all.
Go must provide all of their dependencies via either Go modules with a go.mod file, or a vendor directory, go.mod is created with go mod init example.com/greetngs and updated when run go mod tidy, go.mod only tracks the deps(write a record in it), the downloaded modules is saved at $GOMODCACHE.
In GO111MODULE=off, if a package or a parent folder(parent's parent ...) of a package contains folder named vendor it will be searched for dependencies using the vendor folder as an import path root. While vendor folders can be nested, in most cases it is not advised or needed. when GO111MODULE=off Any package in the vendor folder will be found before the standard library.
go.mod
useful command used within a module
1 | initialize new module in current directory |
project layout
1 | |-- prj |
creating a module(library) used by others
1 | mkdir greetings |
creating a module(runnable application)
1 | mkdir hello |
Importing packages from your module
1 | (base) [root@centos go]# tree |
1 | package main |
vendor
It is a folder found in a module that stores a copy of all the code the module depends on. The code is used to compile the final executable when the go build command is run with GO111MODULE=off.
By default, there is no vendor folder at all, but you can create it with go mod vendor or govendor govendor tool, after this all deps are copied to vendor fold, that means you can build your project without downloading deps if you switch to another machine or the deps are deleted from Internet, you have a total copy of it.
It’s old way, should not use it anymore, refer to migrate to go mod to update your project.
exception
No exception in Go like python or C++, library should return a value and err if want caller check error.
In Go, there is a built-in error type which defines like this
1 | type error interface { |
So that any type who satisfies this interface implements Error() method can be used as error.
fmt.Errorf("error %d", 10) returns struct instance which implements such method- The fmt package formats an error value by calling its Errorf() method.
1 | func great(a, b int)(int, error) { |
recover from panic
defer function is called even panic happens.
When panic is called, including implicitly for run-time errors such as indexing a slice out of bounds or failing a type assertion, it immediately stops execution of the current function and begins unwinding the stack of the goroutine, running any deferred functions along the way. If that unwinding reaches the top of the goroutine's stack, the program dies.
A call to recover() stops the unwinding and returns the argument passed to panic. Because the only code that runs while unwinding is inside deferred functions, recover is only useful inside deferred functions.
One application of recover is to shut down a failing goroutine inside a server without killing the other executing goroutines.
1 | import "fmt" |
1 | package number |
1+2= 3
not support negative adding
cgo(call C in Go)
Cgo lets Go packages call C code. In order to use C code in Go, you first need to import a “pseudo-package”, “C” a special name interpreted by cgo as a reference to C’s name space, and include headers needed by C code when compiling with fixed format.
If the import of "C" is immediately preceded by a comment, that comment, called the preamble, is used as a header when compiling the C parts of the package by gcc!, The preamble may contain any C code, including function and variable declarations and definitions. These may then be referred to from Go code as though they were defined in the package “C”. All names declared in the preamble may be used, even if they start with a lower-case letter.
NOTECFLAGS, CPPFLAGS, CXXFLAGS, FFLAGS and LDFLAGS may be defined with pseudo #cgo directives within these comments to tweak the behavior of the C, C++ or Fortran compiler.
Note: No space line between import “C” and its header comment
1 | /* |
type mapping between C and go
The standard C numeric types are available under the names
- C.char, C.schar (signed char), C.uchar (unsigned char)
- C.short, C.ushort (unsigned short)
- C.int, C.uint (unsigned int)
- C.long, C.ulong (unsigned long), C.longlong (long long), C.ulonglong (unsigned long long)
- C.float, C.double
- The C type void is represented by Go’s unsafe.Pointer.*
- The C types __int128_t and __uint128_t are represented by [16]byte.
- C.struct_person{} refer to
struct person{}defined in C - C.sizeof_struct_person get the len of
struct person{}defined in C
Access struct
- To access a struct, union, or enum type directly, prefix it with struct_, union_, or enum_, as in
C.struct_stat.
sizeof
- The size of any C type T is available as C.sizeof_T, like
C.sizeof_struct_stat == sizeof(struct stat)
pass Go array to C function
- n, err := C.f(&array[0]) // pass address of the first element.
Memory allocations made by C code are unknown to Go’s memory manager.
- When you create a C string with
C.CString(or any C memory allocation) you must remember to free the memory when you’re done with it by calling C.free.
write C within go file
1 | package main |
write C out of go, compile as library, go import the library
sum.c
1 |
|
sum.h
1 | int sum(int a, int b, char* msg); |
Then create shared library
1 | $ gcc -fPIC -c sum.c |
test.go
1 | package main |
1 | $ go run test.go |
Runtime
func NumCPU() int
NumCPU returns the number of logical CPUs usable by the current process.
The set of available CPUs is checked by querying the operating system at process startup. Changes to operating system CPU allocation after process startup are not reflected.
func GOMAXPROCS(n int) int
GOMAXPROCS sets the maximum number of CPUs that can be executing simultaneously and returns the previous setting. It defaults to the value of runtime.NumCPU. If n < 1, it does not change the current setting. This call will go away when the scheduler improves.
func Gosched()
Gosched yields the processor, allowing other goroutines to run. It does not suspend the current goroutine, so execution resumes automatically.
runtime library
concurrency(multiple threads)
The channel introduces many use cases in which channels are used to do data synchronizations among goroutines. In fact, channels are not the only synchronization techniques provided in Go. There are some other synchronization techniques supported by Go. For some specified circumstances, using the synchronization techniques other than channel are more efficient and readable than using channels.
ways to use channel, think chan bool as type
1 | - var m chan bool // bool channel |
A goroutine is a lightweight 'thread' managed by the Go runtime. by default GO creates a pool of linux threads, the number of this pool equals to number of processor, goroutine runs on these threads.
go f(x, y, z)
The evaluation of f, x, y, and z happens in the current goroutine and the execution of f happens in the new goroutine.
goroutines run in the same address space, so access to shared memory must be synchronized. The sync package provides useful primitives.
communication between goroutines
Channels are a typed conduit through which you can send and receive values with the channel operator, <-
1 | ch = make(chan int) // create a channel with buffer size 0, no buffer, which only access int as its message |
By default, send and receive block until the other side is ready. This allows goroutines to synchronize without explicit locks or condition variables.
Receivers always block until there is data to receive. If the channel is unbuffered(buffer size 0), the sender blocks until the receiver has received the value. If the channel has a buffer, the sender blocks only until if the buffer is full, this means waiting until some receiver has retrieved a value.
1 | ch = make(chan int, 10) // buffer is 10, if no one receives, the 11th sending blocks!!! |
Sends to a buffered channel block only when the buffer is full. Receives block when the buffer is empty
A sender can close a channel to indicate that no more values will be sent. Receivers can test whether a channel has been closed by assigning a second parameter to the receive expression: afterv, ok := <- ch
ok is false if there are no more values to receive and the channel is closed, ok is true if more values to receive, even it’s closed!!!
1 | package main |
The loop for i := range c receives values from the channel repeatedly until it is closed.
Note:
- Only the sender should close a channel, never the receiver
Sending on a closed channel will cause a panic.Reading on closed channel, error happens, but not panic!!- For zero buffer channel, send and receive block until the other side is ready
1 | package main |
0
1
1
2
3
5
8
13
21
34
multiple channels
The select statement lets a goroutine wait on multiple communication operations.
A select blocks until one of its cases can run, then it executes that case. the default case in a select runs if no other case is ready(no event on channel), select only works for channel, not socket fd, if you want to monitor multiple fds for high performance use gnet
- if no default case, select quits until one channel is ready!!! otherwise block for ever,
so it's one time execution, if you need to select more time, put it in for loop!!!
It chooses one at random if multiple channels are ready
1 | package main |
0
1
1
2
3
5
8
13
21
34
true
Mutex
What we just want to make sure only one goroutine can access a shared variable at a time to avoid conflicts?
This concept is called mutual exclusion, and the conventional name for the data structure that provides it is mutex.
Go’s standard library provides mutual exclusion with sync.Mutex and its two methods:
1 | import "sync" |
We can define a block of code to be executed in mutual exclusion by surrounding it with a call to Lock and Unlock.
We can also use defer to ensure the mutex will be unlocked as in the Value method.
mutex is not associated with particular goroutine, it’s global and can be accessed by all goroutines, locked when the mutex lock bit is set.
NOTE
- nested is not supported
1
2
3m := sync.Mutex{}
m.Lock()
m.Lock()// block for ever here!!!
1 | package main |
Hi
Bye
WaitGroup
Each sync.WaitGroup value maintains a counter internally. The initial value of the counter is zero.
The *WaitGroup type has three methods: Add(delta int), Done() and Wait().
- we can call the
wg.Add(delta) methodto change the counter value maintained by wg. - the method call
wg.Done()is totally equivalent to the method call wg.Add(-1). - if a call
wg.Add(delta) (or wg.Done()) modifies the counter maintained by wg to negative, panic will happen. - when a goroutine calls wg.Wait(),
- if the counter maintained by wg is already zero, then the call wg.Wait() can be viewed as a no-op.
- otherwise (the counter is positive), the goroutine will enter blocking state. It will enter running state again (a.k.a., the call wg.Wait() returns) when another goroutine modifies the counter to zero, generally by calling wg.Done().
Generally, a WaitGroup value is used for the scenario that one goroutine waits until all of several other goroutines finish their respective jobs.
Note
The
Wait()method can be called in multiple goroutines. When the counter becomes zero, all of them will be notified, in a broadcast way.A WaitGroup value can
be reused after one call to its Wait method returns. But please note that each Add method call with a positive delta that occurs when the counter is zero must happen before any Wait call starts, otherwise, data races may happen.Must
call Add() in main goroutinenot the one runs the job.
1 | package main |
Done:4
Done:2
Done:1
Done:3
Done:0
values:[63 93 53 59 60]
Once
A *sync.Once value has a Do(f func()) method, which takes a solo parameter with type func().
The code in the invoked argument function(doSomething()) is guaranteed to be executed before any once.Do() method call returns.
Generally, a Once value is used to ensure that a piece of code will be executed exactly once in concurrent programming.
1 | package main |
Hello in once
world!
world!
world!
world!
world!
x = 1
Cond
The sync.Cond type provides an efficient way to do notifications among goroutines.
Each sync.Cond value holds a sync.Locker field with name L. The field value is often a value of type *sync.Mutex or *sync.RWMutex. So, in order to use Cron, you must have a mutex as well!!!
c.Wait()must be called when c.L is locked, otherwise, a c.Wait() will cause panic. A c.Wait() call will first push the current caller goroutine into the waiting goroutine queue maintained by c, then call c.L.Unlock() to unlock/unhold the lock c.L. then make the current caller goroutine enter blocking state. Once the caller goroutine is unblocked and enters running state again, c.L.Lock() will be called (in the resumed c.Wait() call) to try to lock and hold the lock c.L again, The c.Wait() call will exit after the c.L.Lock() call returns.a
c.Signal()call willunblock the first goroutinein (and remove it from) the waiting goroutine queue maintained by c, if the queue is not empty.a
c.Broadcast()call willunblock all the goroutinesin (and remove them from) the waiting goroutine queue maintained by c, if the queue is not empty.
cond.Broadcast() and cond.Signal() are not required to be called when cond.L is locked. you can also call them after unlock.
1 | package main |
[ ]
[ e ]
[ b e ]
[a b e ]
[a b c e ]
[a b c e h ]
[a b c e f h ]
[a b c d e f h ]
[a b c d e f h j]
[a b c d e f g h j]
[a b c d e f g h i j]
atomic
go provides atomic operations Add、CompareAndSwap、Load、Store、Swap from "sync/atomic"
1 | func AddInt32(addr *int32, delta int32) (new int32) |
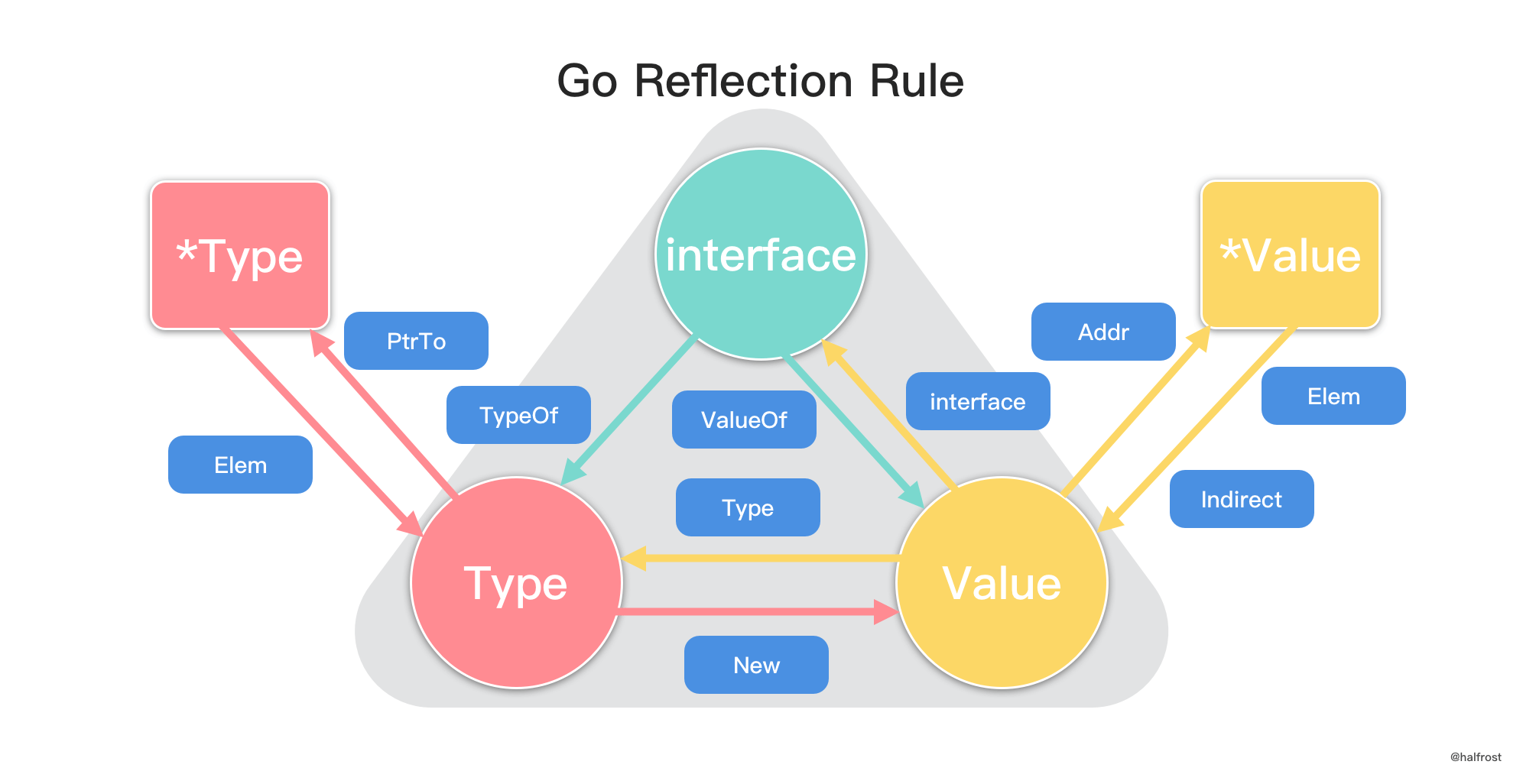
reflection
from specific type to generic type
you can convert any type to interface {} just for parameter passing.
1 | var a int = 10 |
from interface to specific type
As any type can be converted to interface{} type, but how can we convert it back to particular type.
A type assertion provides access to an interface value’s underlying concrete value.
t := i.(T) If i does not hold a T, the statement will trigger a panic.
This statement asserts that the interface value i holds the concrete type T and assigns the underlying T value to the variable t.
To test whether an interface value holds a specific type, a type assertion can return two values: the underlying value and a boolean value that reports whether the assertion succeeded.
t, ok := i.(T)
If i holds a T(i is an instance of T), then t will be the underlying value and ok will be true.
If not, ok will be false and t will be the zero value of type T, and no panic occurs.
T is generic type, it can be int or *int(*int is also a type)
generic value, v, ok := i.(T) // i is var of interface{}
1 | if v, ok := i.(int); ok { |
type switch(only valid for switch)
A type switch is like a regular switch statement, but the cases in a type switch specify types (not values), and those values are compared against the type of the value held by the given interface value.
1 | func do(i interface{}) { |
Advanced feature between interface and specfic type
you can convert any type to interface {} just for parameter passing
but as interface {} has no method, hence you can NOT get more information about the type/value it behinds, so refection package gives advanced feature.
reflect implements run-time reflection, allowing a program to manipulate objects with arbitrary types. The typical use is to take a value with static type interface{} and extract its dynamic type information by calling TypeOf(), which returns a Type(an interface defined in reflect package).
A call to ValueOf() returns a Value(an interface defined in reflect package) representing the run-time data. Zero takes a Type and returns a Value representing a zero value for that type.
reflect.Type(
type interface {}) returned by reflect.Typeof(any instance)- rType implements generic methods defined by reflect.Type
- mapType, ptrType, structType(which embed rType) etc implement specific methods defined reflect.Type which are valid for its type, so specific type implements all methods defined by reflect.Type
reflect.Value(
type Value struct {}) returned by reflect.Valueof(any instance)- Value has generic methods called by all values
- Value has specific methods which are valid for specific type
Method of specific type
| Kind | Methods applicable |
|---|---|
| Int* | Bits |
| Uint* | Bits |
| Float* | Bits |
| Complex* | Bits |
| Array | Elem, Len |
| Chan | ChanDir, Elem |
| Func | In, NumIn, Out, NumOut, IsVariadic |
| Map | Key, Elem |
| Ptr | Elem |
| Slice | Elem |
| Struct | Field, FieldByIndex, FieldByName,FieldByNameFunc, NumField |
Type.Elem() returns a type’s element type.
Type.PtrTo() returns the pointer type with element t.
- For example, if t represents type Foo, PtrTo(t) represents *Foo.
v.Indirect() returns the value that v points to(v is pointer Value)
v := reflect.Valueof(&Person{Name: "tom"}), vv := v.Indirect()
v.Addr() returns the pointer’s Value (v is object Value)
v := reflect.Valueof(Person{Name: "tom"}), vp: = v.Addr()
Ref
1 | package main |
p := Person{}
type :struct { Name string "k1:\"v1\" k2:\"v2\""; 𒀸id int }
size(byte): 24
numField: 2
numMethod: 0
align: 8
fieldalign: 8
tom 10 tom 10
Say method not found
field name: Name, type: string, Tag: k1:"v1" k2:"v2"
p := Person{}
type :struct { Name string "k1:\"v1\" k2:\"v2\""; 𒀸id int }
size(byte): 24
numField: 2
numMethod: 0
align: 8
fieldalign: 8
name= tom
method Say not found
{tom 10} {tom 10}
import cycle
Cyclic dependency is fundamentally a bad design and is a compile-time error in Golang(error: import cycle not allowed). we should change our design to solve this in either way.
Solve import cycle
- put them in the same package
- use interface to solve the import cycle issue
1 | dep |
1 | package a |
1 | package b |
1 | package main |
Soloution
we must introduce an interface in a new package say c. This interface will have all the methods that are in struct A and are accessed by struct B.
1 | package c |
1 | package a |
1 | package b |
1 | package main |
Deep copy
There is no deep copy built-in function provided by Go, if you want to deep copy, you have to copy it by your self, go only does shadow copy.
- For channel, slice, dict, interface, pointer, assigned var points to same memory.
- For struct, non-point, assigned var has its own memory, shadow copied.
- Deep copy for map two ways.
- Marshal –> then Unmarshal
- iterate each item, then do copy, if item is a map, recursive deep is needed!!!
- copy for slice,
copy(dst, src), not recursive, not deep.
Go does the same thing as C language
1 | a := []int{1,2,3} |
Tips
Anonymous struct type
Most of time, if we frequently use a struct type, we should define a new type, use it for short like this
1 | type Student struct { |
But we still can use a unnamed struct if only use it for several times, like this
1 | import "fmt" |
Anonymous function
Anonymous function is a function without name, it’s mostly used in two cases
used as goruntine entry pointsaved in function object, then call it later.used as return value.defer function.
1 | func test { |
Reader and Writer
The io package specifies the io.Reader interface, which represents the read end of a stream of data.
The Go standard library contains many implementations of this interface, including files, network connections, compressors, ciphers, and others.
The io.Reader interface has a Read method:
func (T) Read(b []byte) (n int, err error)
Read populates the given byte slice(should be create first with make()) with data and returns the number of bytes populated and an error value. It returns an io.EOF error when the stream ends.
1 | package main |
n = 8 err = <nil> b = [72 101 108 108 111 44 32 82]
b[:n] = "Hello, R"
n = 6 err = <nil> b = [101 97 100 101 114 33 32 82]
b[:n] = "eader!"
n = 0 err = EOF b = [101 97 100 101 114 33 32 82]
b[:n] = ""
never use break for each case in switch/select
As go break each matched case automatically, there is no need to use break for each case explicitly in case you want to break in the middle of the case.
1 | tick := time.NewTicker(2 * time.Second) |
Handle OS difference
Most of time, go code can shared by different OS like linux and windows etc, but in some case, we may need to handle special cases that depends on OS, hence we need to know the OS in Go code $GOOS gives the way for you to deal that.
1 | package main |
HTTP over Unix
1 | // A quick and dirty demo of talking HTTP over Unix domain sockets |
WaitGroup vs Channel
Actually, there are designed for different scenarios, If you are dispatching one-off jobs to be run in parallel without needing to know the results of each job, then you can use a WaitGroup. But if you need to collect the results from the goroutines then you should use a channel. channel is designed to pass data while WaitGrop for wait jobs(which runs in goroutine) to finish.
waitgroup
1 | package main |
notify channel
1 | package main |
if you have several jobs to run, waitgroup is best choice to use!!
1 | package main |
job done
job done
got two jobs done
do we need to close(channel) explicitly
No, It’s OK to leave a Go channel open forever and never close it. When the channel is no longer used(no read and write), it will be garbage collected.
It is only necessary to close a channel explicitly if the receiver is looking for a close. Closing the channel is a control signal on the channel indicating that no more data follows, or to notify goroutine to quit otherwise it may blocking for ever
Danger
- closing a closed channel will panic, so it is dangerous to close a channel if the closers don’t know whether or not the channel is closed.
- sending values to a closed channel will panic, so it is dangerous to send values to a channel if the senders don’t know whether or not the channel is closed.
Rule to close if required
- don’t close a channel from the receiver side.
- don’t close a channel if the channel has multiple concurrent senders.
In other words, we should only close a channel in a sender goroutine if the sender is the only sender of the channel. more solution to close a channel, refer to channel closing
1 | package main |
test return, but goroutine is blocking
goroutine blocks
goroutine quit
print value of struct pointer embeded in another struct
By default, struct pointer printed with its content if it’s not embeded, but if struct pointer as field of another struct, the pointer address is printed, As when call print, the String() of that type is called, but by default golang does not provide String() for struct pointer, but struct only, that’s why pointer address is printed, In order to print pinter content(not address), there are several ways we can use
- iterate each pointer in struct, print it with
fmt.Println("%s", *p) with json.Marshel(), but only exported field are printed- For each pointer, implement its
func (s *XX)String()string{}method
1 | ackage main |
1 | [{tom 1} {jack 2}] |
1 | package main |
[{"Name":"tom","Cls":{"Id":1}},{"Name":"jack","Cls":{"Id":2}}]
block forever in go
1 | func blockForever() { |
Channel with timeout
Actually, there is no timeout parameter of API when reading/writing channel, so we use other way to do this.
Way1
1 | func main() { |
Way2
1 | ch := make(chan string) |
Good reason to use context
Another advantage of using context is that it can take advantage of its natural transmission characteristics in multiple goroutines, so that all goroutines that pass the context can receive cancellation notifications at the same time. we can call cancel() once, while quits all gorotines who listen on it..