k8s_ha
Introduction
One of the main advantages of Kubernetes is how it brings greater reliability and stability to the container-based distributed application, through the use of dynamic scheduling of containers. But, how do you make sure Kubernetes itself stays up when a component or its master node goes down?
Kubernetes High-Availability is about setting up Kubernetes, along with its supporting components in a way that there is no single point of failure. A single master cluster can easily fail, while a multi-master cluster uses multiple master nodes, each of which has access to same worker nodes. In a single master cluster the important component like API server, controller manager lies only on the single master node and if it fails you cannot create more services, pods etc. However, in case of Kubernetes HA environment, these important components are replicated on multiple masters(usually three masters) and if any of the masters fail, the other masters keep the cluster up and running.
HA topology
There two options for configuring the topology of your highly available (HA) Kubernetes clusters.
You can set up an HA cluster:
- With stacked control plane nodes, where etcd nodes are colocated with control plane nodes
- With external etcd nodes, where etcd runs on separate nodes from the control plane
Stacked etcd topology
A stacked HA cluster is a topology where the distributed data storage cluster provided by etcd is stacked on top of the cluster formed by the nodes managed by kubeadm that run control plane components.
Each control plane node runs an instance of the kube-apiserver, kube-scheduler, and kube-controller-manager. The kube-apiserver is exposed to worker nodes using a load balancer.
Each control plane node creates a local etcd member and this etcd member communicates only with the kube-apiserver of this node. The same applies to the local kube-controller-manager and kube-scheduler instances.
This topology couples the control planes and etcd members on the same nodes
Proc:
- It is simpler to set up than a cluster with external etcd nodes, and simpler to manage for replication.
Cons
- A stacked cluster runs the risk of failed coupling. If one node goes down, both an etcd member and a control plane instance are lost, and redundancy is compromised. You can mitigate this risk by adding more control plane nodes.
This is the default topology in kubeadm. A local etcd member is created automatically on control plane nodes when using kubeadm init and kubeadm join –control-plane.

External etcd topology
An HA cluster with external etcd is a topology where the distributed data storage cluster provided by etcd is external to the cluster formed by the nodes that run control plane components.
Like the stacked etcd topology, each control plane node in an external etcd topology runs an instance of the kube-apiserver, kube-scheduler, and kube-controller-manager. And the kube-apiserver is exposed to worker nodes using a load balancer. However, etcd members run on separate hosts, and each etcd host communicates with the kube-apiserver of each control plane node.
This topology decouples the control plane and etcd member.
Proc:
- It provides an HA setup where losing a control plane instance or an etcd member has less impact and does not affect the cluster redundancy as much as the stacked HA topology.
Cons:
- This topology requires twice the number of hosts as the stacked HA topology. A minimum of three hosts for control plane nodes and three hosts for etcd nodes are required for an HA cluster with this topology.

API server LB and HA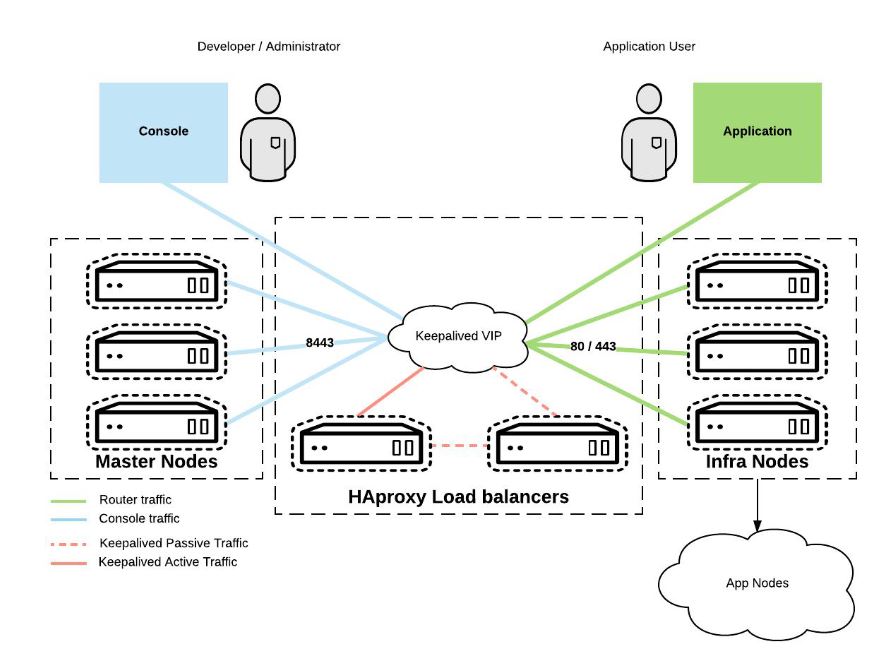
Note
- use HA proxy to expose virtual IP that’s used by worker node for connection, behind HA proxy is the real API server that serves the request.
- use Keepalived for HA proxy HA, if one HA proxy is down, the other takes over.