k8s_autoscale
Introduction
Autoscaling allows you to dynamically adjust to demand without intervention from the individuals in charge of operating the cluster.
Kubernetes autoscaling helps optimize resource usage and costs by automatically scaling a cluster up and down in line with demand.
Kubernetes enables autoscaling at the cluster/node level as well as at the pod level.
Autoscaler
Autoscaling eliminates the need for constant manual reconfiguration to match changing application workload levels. Kubernetes can autoscale by adjusting the capacity (vertical autoscaling) and number (horizontal autoscaling) of pods, and/or by adding or removing nodes in a cluster (cluster autoscaling).
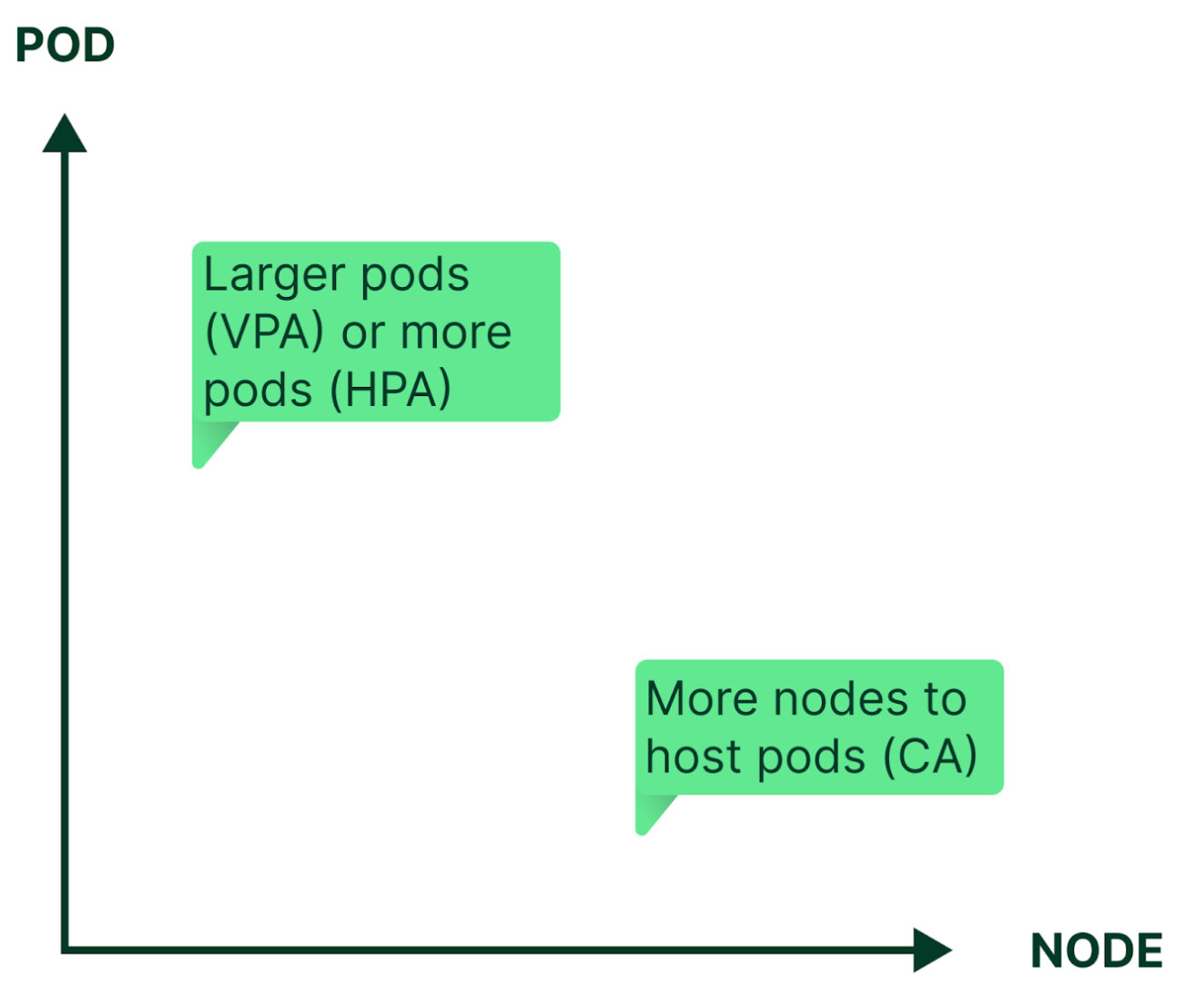
There are actually three autoscaling features for Kubernetes: Horizontal Pod Autoscaler, Vertical Pod Autoscaler, and Cluster Autoscaler. Let’s take a closer look at each and what they do.
Horizontal Pod Autoscaler(HPA)
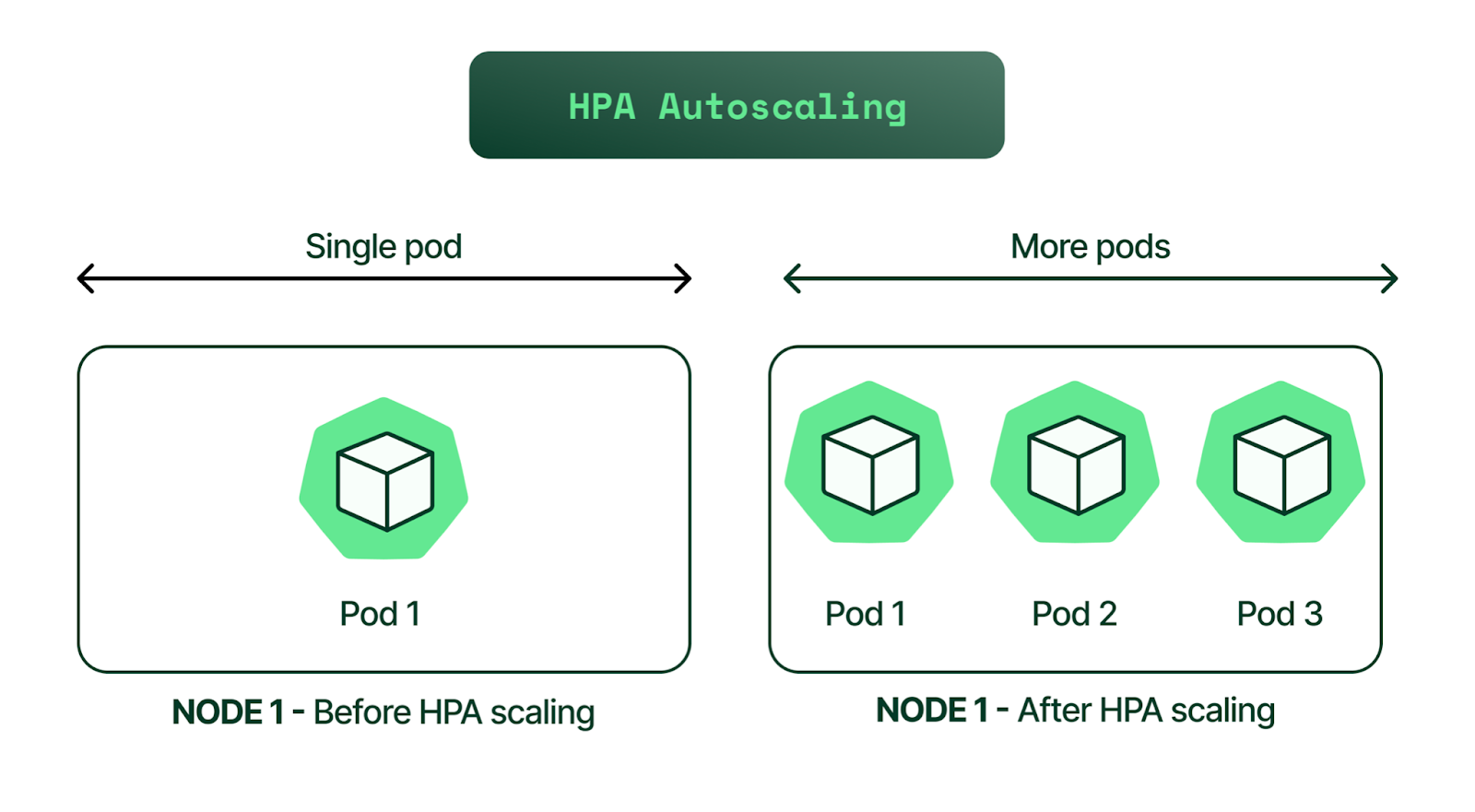
Horizontal scaling, which is sometimes referred to as “scaling in/out,” allows Kubernetes administrators to dynamically (i.e., automatically) increase or decrease the number of running pods as your application’s usage changes.
A cluster operator declares their target usage for metrics, such as CPU or memory utilization, as well their desired maximum and minimum desired number of replicas,. The cluster will then reconcile the number of replicas accordingly, and scale up or down the number of running pods based on their current usage and the desired target.
Vertical Pod Autoscaler(VPA)
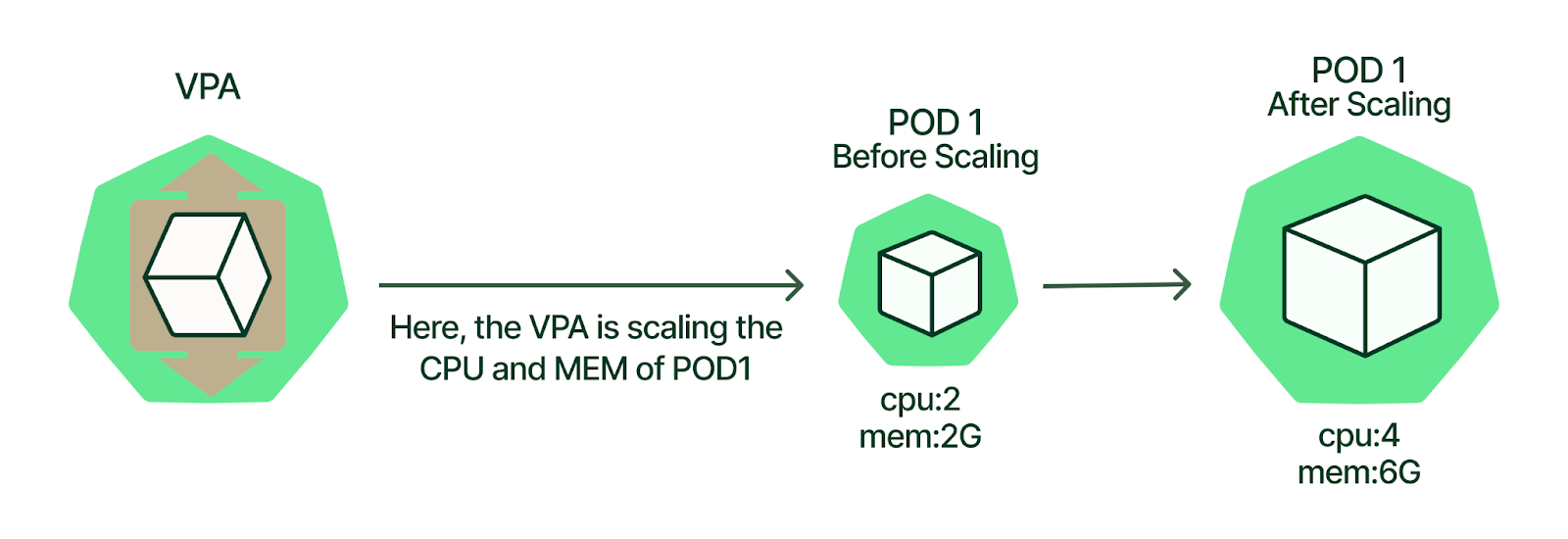
VPA refers to adding more resources (such as CPU or memory) to an existing machine. it’s sometimes referred to as “scaling up/down”
The cluster operator declares their target usage for metrics, such as CPU or memory utilization. The cluster will then reconcile the size(CPU, Memory) of the service’s pod or pods based on their current usage and the desired target.
Vertical Pod Autoscaler (VPA) frees the users from necessity of setting up-to-date resource limits and requests for the containers in their pods. When configured, it will set the requests automatically based on usage and thus allow proper scheduling onto nodes so that appropriate resource amount is available for each pod. It will also maintain ratios between limits and requests that were specified in initial containers configuration.
It can both down-scale pods that are over-requesting resources, and also up-scale pods that are under-requesting resources based on their usage over time.
Autoscaling is configured with a Custom Resource Definition object called VerticalPodAutoscaler. It allows to specify which pods should be vertically autoscaled as well as if/how the resource recommendations are applied.
For each VPA resource, there are three modes in which VPAs operate:
- “Auto”: VPA assigns resource requests on pod creation as well as updates them on existing pods using the preferred update mechanism. Currently this is equivalent to “Recreate” (see below). Once restart free (“in-place”) update of pod requests is available, it may be used as the preferred update mechanism by the “Auto” mode. NOTE: This feature of VPA is experimental and may cause downtime for your applications.
- “Recreate”: VPA assigns resource requests on pod creation as well as updates them on existing pods by evicting them when the requested resources differ significantly from the new recommendation (respecting the Pod Disruption Budget, if defined). This mode should be used rarely, only if you need to ensure that the pods are restarted whenever the resource request changes. Otherwise prefer the “Auto” mode which may take advantage of restart free updates once they are available. NOTE: This feature of VPA is experimental and may cause downtime for your applications.
- “Initial”: VPA only assigns resource requests on pod creation and never changes them later.
- “Off”: VPA does not automatically change resource requirements of the pods. The recommendations are calculated and can be inspected in the VPA object.
VPA does not modify the template in the deployment, but the actual requests of the pods are updated
1 | containers: |
enable VPA
1 | # step1: enable metric server https://github.com/kubernetes-incubator/metrics-server |
Note
Updating running pods is an experimental feature of VPA. Whenever VPA updates the pod resources the pod is recreated, which causes all running containers to be restarted. The pod may be recreated on a different node
Vertical Pod Autoscaler should not be used with the Horizontal Pod Autoscaler (HPA) on CPU or memory at this moment. However, you can use VPA with HPA on custom and external metrics.
VPA recommendation might exceed available resources (e.g. Node size, available size, available quota) and cause pods to go pending. This can be partly addressed by using VPA together with Cluster Autoscaler.
Multiple VPA resources matching the same pod have undefined behavior.
Cluster Autoscaler(CA)
HPA and VPA essentially make sure that all of the services running in your cluster can dynamically handle demand while not over-provisioning during slower usage periods. That’s a good thing.
It’s what allows for the autoscaling of the cluster itself, increasing and decreasing the number of nodes available for your pods to run on.
Cluster Autoscaler will reach out to a cloud provider’s API and scale up or down the number of nodes attached to the cluster accordingly, so it’s different config for different cloud providers, only works in cloud env.
Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster when one of the following conditions is true:
- there are pods that failed to run in the cluster due to insufficient resources(to increase node)
- there are nodes in the cluster that have been underutilized for an extended period of time and their pods can be placed on other existing nodes.(decrease node, migrate pod to other nodes).
Here is an example for Alibaba Cloud.
Cloud provider that has cluster autoscaler provided
- AWS
- GKE
- Azure
- AliCloud
…