distribute_zookeeper
Overview
Apache ZooKeeper is basically a distributed(cluster) coordination service for managing a large set of hosts. Coordinating and managing the service in the distributed environment is really a very complicated process. Apache ZooKeeper, with its simple architecture and API, solves this issue. ZooKeeper allows the developer to focus on the core application logic without being worried about the distributed nature of the application.
Apache ZooKeeper is basically a service that is used by the cluster to coordinate between themselves and maintain the shared data with the robust synchronization techniques.
Apache ZooKeeper is itself a distributed application providing services for writing the distributed application.
Distributed Application
A distributed application is the application that can run on the multiple systems in a network simultaneously by coordinating among themselves in order to complete the specific task in an efficient manner. The distributed application can complete the complex and the time-consuming tasks in minutes as compared to the non-distributed application that will take hours to complete the task.
The distributed application uses the computing capabilities of all the machines involved. We can further reduce the time to complete the task by configuring the distributed application to run on more nodes in the cluster.
A distributed application consists of two parts, that is, Server and Client application. The server applications are actually distributed and they have a common interface so that the clients can connect to any server in a cluster and get the same result. The client applications were the tools for interacting with the distributed application.
Benefits of Distributed Applications
- Reliability − If the single node or the few systems fails, then it doesn’t make the whole system fail.
- Scalability − We can easily increase the performance when needed by adding more machines with the minor changes in the application configuration without any downtime.
- Transparency − It hides the complexity of the entire system and depicts itself as a single entity or application.
Zookeeper
The various services provided by Apache ZooKeeper are as follows
- Naming service − This service is for identifying the nodes in the cluster by the name. This service is similar to DNS, but for nodes.
- Configuration management − This service provides the latest and up-to-date configuration information of a system for the joining node.
- Cluster management − This service keeps the status of the Joining or leaving of a node in the cluster and the node status in real-time.
- Leader election − This service elects a node as a leader for the coordination purpose.
- Locking and synchronization service − This service locks the data while modifying it. It helps in automatic fail recovery while connecting the other distributed applications such as Apache HBase.
- Highly reliable data registry − It offers data availability even when one or a few nodes goes down.
Architecture
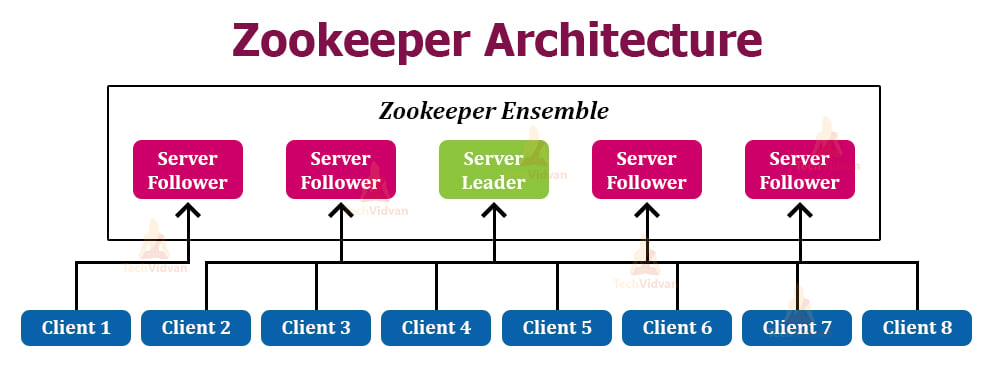
Server: The server sends an acknowledge when any client connects. In the case when there is no response from the connected server, the
client automatically redirectsthe message to another server.Client: Client is one of the nodes in the distributed application cluster. It helps you to accesses information from the server. Every client sends a message to the server at regular intervals that helps the server to know that the client is alive.
Leader: One of the servers is designated a Leader. It gives all the information to the clients as well as an acknowledgment that the server is alive. It would performs
automatic recovery if any of the connected nodes failed.Follower: Server node which follows leader instruction is called a follower.
- Client
read requests are handled by the correspondingly connected Zookeeper server - The client
writes requests are handled by the Zookeeper leader.
- Client
Ensemble/Cluster: Group of Zookeeper servers which is called ensemble or a Cluster. You can use ZooKeeper infrastructure in the cluster mode to have the system at the optimal value when you are running the Apache.
Writes in Zookeeper
In Zookeeper, all the writes go through the Master(leader) node. Due to this all the writes are sequential. While performing the write operation in Zookeeper, each of the servers which are attached to that client persists data along with the master. This updates all the servers(follower, leader etc) about the data. This also means that we cannot make concurrent writes. The guarantee for linear writes can be problematic if we use Zookeeper for writing dominant workload.
Reads in Zookeeper
Zookeeper is best at reads. Reads can be concurrent. In Zookeeper, concurrent reads are performed as each client is attached to a different server and all the clients can read data from the servers simultaneously. It may sometimes happen that the client may have an outdated view. This gets updated within a little time.
Data Model

- The zookeeper data model follows a Hierarchal namespace where each node is called a ZNode. A node is a system where the cluster runs.
Key Znode features you need to know:
- Znodes can store data and have children Znode at same time
- It can store information like the current version of data changes in Znode, transaction Id of the latest transaction performed on the Znode.
- Each znode can have its access control list(ACL), like the permissions in Unix file systems. Zookeeper supports: create, read, write, delete, admin(set/edit permissions) permissions.
- Znodes ACL supports username/password-based authentication on individual znodes too.
- Clients can set a watch on these Znodes and get notified if any changes occur in these znodes.
- These change/events could be a change in znodes data, change in any of znodes children, new child Znode creation or if any child Znode is deleted under the znode on which watch is set.
The main purpose of the Zookeeper data model is:
- To maintain the
synchronization in a zookeeper cluster - To explain the
metadata of each Znode.
Node Types in Zookeeper
Persistence Znode
Persistence Znode are the nodes thatstay alive even when the client who created the node is disconnected. All the server nodes in the ensemble assume themselves to be the Persistence Znodes, To remove these Znodes, you need to delete them manually(use delete operation)Ephemeral Znode
The Ephemeral Znode are the nodes that stay alive until the client is alive or connected to them.They die when the client gets disconnected. Ephemeral Znode are not allowed to have children. They play an important role in the leader elections.
Zookeeper clients keep sending the ping request to keep the session alive. If Zookeeper does not see any ping request from the client for a period of configured session timeout, Zookeeper considers the client as dead and deletes the client session and the Znode created by the client.Sequential Znode
Sequential Znode can be either the Persistence Znode or the Ephemeral Znode. While creating a new Sequential Znode, the ZooKeepersets the path of the Znode by attaching the 10 digit sequence number to the original name. This znode plays an important role in the Locking and Synchronization
Watches
Zookeeper, a watch event is a one-time trigger which is sent to the client that set watch. It occurred when data from that watch changes. watch allows clients to get notifications when znode changes. read operations like getData(), getChidleren(), exist have the option of setting a watch.
Watches are ordered, the order of watch events corresponds to the order of the updates. A client will able to see a watch event for znode before seeing the new data which corresponds to that znode.
Access Control list
ZNode ACL
Zookeeper uses ACLs to control access to its znodes. ACL is made up of a pair of (Scheme: id, permission)
Build in ACL schemes:
- world: has a single id, anyone
- auth: Not use any id, It represents any authenticated user
- digest: use a username: password
- host: Allows you to use client’s hostname as ACL id identity
- IP: use the client host IP address as ACL id identity
ACL Permissions:
- CREATE
- READ
- WRITE
- DELETE
- ADMIN
E.x. (IP: 192.168.0.0/16, READ)
Session
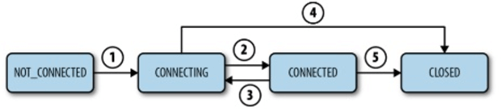
- Before executing any request, it is important that the client must establish a session with service
- All operations clients are sent to service are automatically associated with a session
- The client may connect to any server in the cluster. But it will
connect to only a single server - The session provides “order guarantees”.
The requests in the session are executed in FIFO order - The main states for a session are 1) Connecting, 2) Connected 3) Closed 4) Not Connected.
Leader Selection
We will discuss three algorithms for the leader election.
Approach 1:
A client(any server belonging to the cluster) creates a persistent znode /election in Zookeeper.
All clients add a watch to /election znode and listen to any children znode deletion or addition under /election znode.
Now each server joining the cluster will try to create an ephemeral znode /leader under node /election with data as hostname, ex: node1.domain.com
Since multiple servers in the cluster will try to create znode with the same name(/leader), only one will succeed, and that server will be considered as a leader.
Once all servers in the cluster completes above step, they will call getChildren(“/election”) and get the data(hostname) associated with child znode “/leader”, which will give the leader’s hostname.
At any point, if the leader server goes down, Zookeeper will kill the session for that server after the specified session timeout. In the process, it will delete the node /leader as it was created by leader server and is an ephemeral node and then Zookeeper will notify all the servers that have set the watch on /election znode, as one of the children has been deleted.
Once all server gets notified that the leader is dead or leader’s znode(/leader) is deleted, they will retry creating “/leader” znode and again only one server will succeed, making it a new leader.
Once the /leader node is created with the hostname as the data part of the znode, zookeeper will again notify all servers (as we have set the watch in step 2).
All servers will call getChildren() on “/election” and update the new leader in their memory.
The problem with the above approach is, each time /leader node is deleted,
Zookeeper will send the notification to all servers and all servers will try to write to zookeeper to become a new leader at the same time creating a herd effect. If we have a large number of servers, this approach would not be the right idea.
Ways to avoid, herd effect could be:
(i) by restricting the number of servers that take part in the election and allow only a few servers to update /election znode
OR
(ii) by using sequential znode, which I will explain in the next approach.
Approach 2: Using Ephemeral Sequential Znode
A client(any server belonging to the cluster) creates a persistent znode /election.
All clients add a watch to /election znode and listen to any children znode deletion or addition under /election znode.
Now each server joining the cluster will try to create an ephemeral sequential znode /leader-<sequential number> under node /election with data as hostname, ex: node1.domain.com
Let’s say three servers in a cluster created znodes under /election, then the znode names would be:
/election/leader-00000001
/election/leader-00000002
/election/leader-00000003
Znode with least sequence number will be automatically considered as the leader.
Once all server completes the creation of znode under /election, they will perform getChildren(“/election”) and get the data(hostname) associated with least sequenced child node “/election/leader-00000001”, which will give the leader hostname.
At any point, if the current leader server goes down, Zookeeper will kill the session for that server after the specified session timeout. In the process, it will delete the node “/election/leader-00000001” as it was created by the leader server and is an ephemeral node and then Zookeeper will send a notification to all the server that was watching znode /election.
Once all server gets the leader’s znode-delete notification, they again fetch all children under /election znode and get the data associated with the child znode that has the least sequence number(/election/leader-00000002) and store that as the new leader in its own memory.
In this approach, we saw, if an existing leader dies, the servers are not sending an extra write request to the zookeeper to become the leader, leading to reduce network traffic.
But, even with this approach, we will face some degree of herd effect we talked about in the previous approach. When the leader server dies, notification is sent to all servers in the cluster, creating a herd effect.
But, this is a design call that you need to take. Use approach 1 or 2, if you need all servers in your cluster to store the current leader’s hostname for its purpose.
If you do not want to store current leader information in each server/follower and only the leader needs to know if he is the current leader to do leader specific tasks. You can further simplify the leader election process, which we will discuss in approach 3.
Approach 3: Using Ephemeral Sequential Znode but notify only one server in the event of a leader going down.
Create a persistent znode /election.
Now each server joining the cluster will try to create an ephemeral sequential znode /leader-<sequential number> under node /election with data as hostname, ex: node1.domain.com
Let’s say three servers in a cluster created znodes under /election, then the znode names would be:
/election/leader-00000001
/election/leader-00000002
/election/leader-00000003
Znode with least sequence number will be automatically considered as a leader.
Here we will not set the watch on whole/election znode for any children change(add/delete child znode), instead, each server in the cluster will set watch on child znode with one less sequence.
The idea is if a leader goes down only the next candidate who would become a leader should get the notification.
So, in our example:
- The server that created the znode /election/leader-00000001 will have no watch set.
-The server that created the znode /election/leader-00000002 will watch for deletion of znode /election/leader-00000001
-The server that created the znode /election/leader-00000003 will watch for deletion of znode /election/leader-00000002
Then, if the current leader goes down, zookeeper will delete the node /election/leader-00000001 and send the notification to only the next leader i.e. the server that created node /election/leader-00000002
That’s all on leader election logic. These are simple algorithms. There could be a situation when you want only those servers to take part in a leader election which has the latest data if you are creating a distributed database.
In that case, you might want to create one more node that keeps this information, and in the event of the leader going down, only those servers that have the latest data can take part in an election.
Distributed Locks
Suppose we have “n” servers trying to update a shared resource simultaneously, say a shared file. If we do not write these files in a mutually exclusive way, it may lead to data inconsistencies in the shared file.
We will manipulate operations on znode to implement a distributed lock, so that, different servers can acquire this lock and perform a task.
The algorithm for managing distributed locks is the same as the leader election with a slight change.
Instead of the /election parent node, we will use /lock as the parent node.
The rest of the steps will remain the same as in the leader election algorithm. Any server which is considered a leader is analogous to server acquiring the lock.
The only difference is, once the server acquires the lock, the server will perform its task and then call the delete operation on the child znode it has created so that the next server can acquire lock upon delete notification from zookeeper and perform the task.
Use cases
Group Membership/Managing Cluster state
In Zookeeper it is pretty simple to maintain group membership info using persistent and ephemeral znodes. I will talk about a simple case where you want to maintain information about all servers in a cluster and what servers are currently alive.
We will use a persistent znode to keep track of all the servers that join the cluster and zookeeper’s ability to delete an ephemeral znodes upon client session termination will come handy in maintaining the list of active/live servers.
Create a parent znode /all_nodes, this znode will be used to store any server that connects to the cluster.
Create a parent znode /live_nodes, this znode will be used to store only the live nodes in the cluster and will <store ephemeral child znodes>. If any server crashes or goes down, respective child ephemeral znode will be deleted.
Any server connecting to the cluster will create <a new persistent znode> under /all_nodes say /node1.domain.com. Let’s say another two node joins the cluster. Then the znode structure will look like:
/all_nodes/node1.domain.com
/all_nodes/node2.domain.com
/all_nodes/node3.domain.com
You can store any information specific to the node in znode’s data
Any server connecting to the cluster will create <a new ephemeral znode> under /live_nodes say /node1.domain.com. Let’s say another two-node joins the cluster. Then the znode structure will look like:
/live_nodes/node1.domain.com
/live_nodes/node2.domain.com
/live_nodes/node3.domain.com
Add a watch for any change in children of /all_nodes. If any server is added or deleted to/from the cluster, all server in the cluster needs to be notified.
Add a watch for any change in children of /live_nodes. This way all servers will be notified if any server in the cluster goes down or comes alive.
deploy
As for demo only, we start only one zookeeper instance(standalone mode), in production env, it’s better start a zookeeper cluster which may have 3, 5, odd nodes for performance and HA.
1 | # ubuntu18 |
client CLI command
1 | $ bin/zkCli.sh |
Three nodes cluster
each node must install zookeeper with cfg
node1 zoo.cfg
1 | tickTime=2000 |
node2 zoo.cfg
1 | zoo.cfg: |
node3 zoo.cfg
1 | zoo.cfg: |
FAQ
why we need more than one zookeeper servers?
Two main reason: high availability and performance
why is zookeeper server nubmer odd?
because even and odd have the same high availability.
how does zookeeper handle inconsistence?
it handles the inconsistency of data by atomicity, using ZAB protocol