k8s_faq
Pods
why pod is in pending status?
1 | # pods === pod |
pod is restarted, how can I see previous container log
1 | $ kubectl logs mypod --previous |
how can I check why pod is restart
1 | $ kubectl describe po mypod |
how can I check liveness setting for a pod
1 | $ kubectl describe po mypod |
how pod the service internal cluster ip after it knows the service name?
1 | $ kubectl get svc |
by environment
if pod is created after service, several variables are passed to pod by env
1 | # check env on a pod which is backend of a service |
by DNS server
Actually, each pod configure a internal DNS server(dns service at kube-system)
1 | $ kubectl exec kubia-vtzwq -- cat /etc/resolv.conf |
Here dns server is a service cluster ip of kube-system
1 | $ kubectl get svc -n=kube-system -o wide |
how to support tls in Ingress
1 | $ openssl genrsa -out tls.key 2048 |
1 | apiVersion: extensions/v1beta1 |
why needs headless service(no ClusterIP)
In some case, you want to know all endpoints of a service by internal DNS lookup, if service has ClusterIP, so dns server only returns the ClusterIP of the service, but for headless service, it returns several, each record each for a endpoint.
For headless Services, a cluster IP is not allocated, kube-proxy does not handle these Services, and there is no load balancing or proxying done by the platform for them.
DNS server here provides service<—–>IP mapping
- cluster service, return ClusterIP
- headless service, return IP(s) of each endpoint(pod).
1 | apiVersion: v1 |
directly talk to api server by restful API, skip kubectl
In some cause, we may no kubectl installed or we want to use restful API directly talking with api server from source source code like js/python, there are API reference with example, but first you need to authenticate with server first, either by your self, or use kube-proxy which will do this for you.
1 | # on one node |
how to use host network directly for pod
1 | apiVersion: apps/v1 |
how to limit resource used by container
There are two kinds resource check for K8S pod, but it’s set at each containers of that pod separately.
- request: schedule to node only if it can proivde these resource, used by scheduler
- limits: how much cpu/memory container can use
1 | containers: |
Operator vs Helm
They both serve the same basic goal of helping to install and configure apps in Kubernetes. But they do so in different ways. Depending on factors like how much control you want and how important ongoing application lifecycle management is, an operator might be better than a Helm chart, or vice versa.
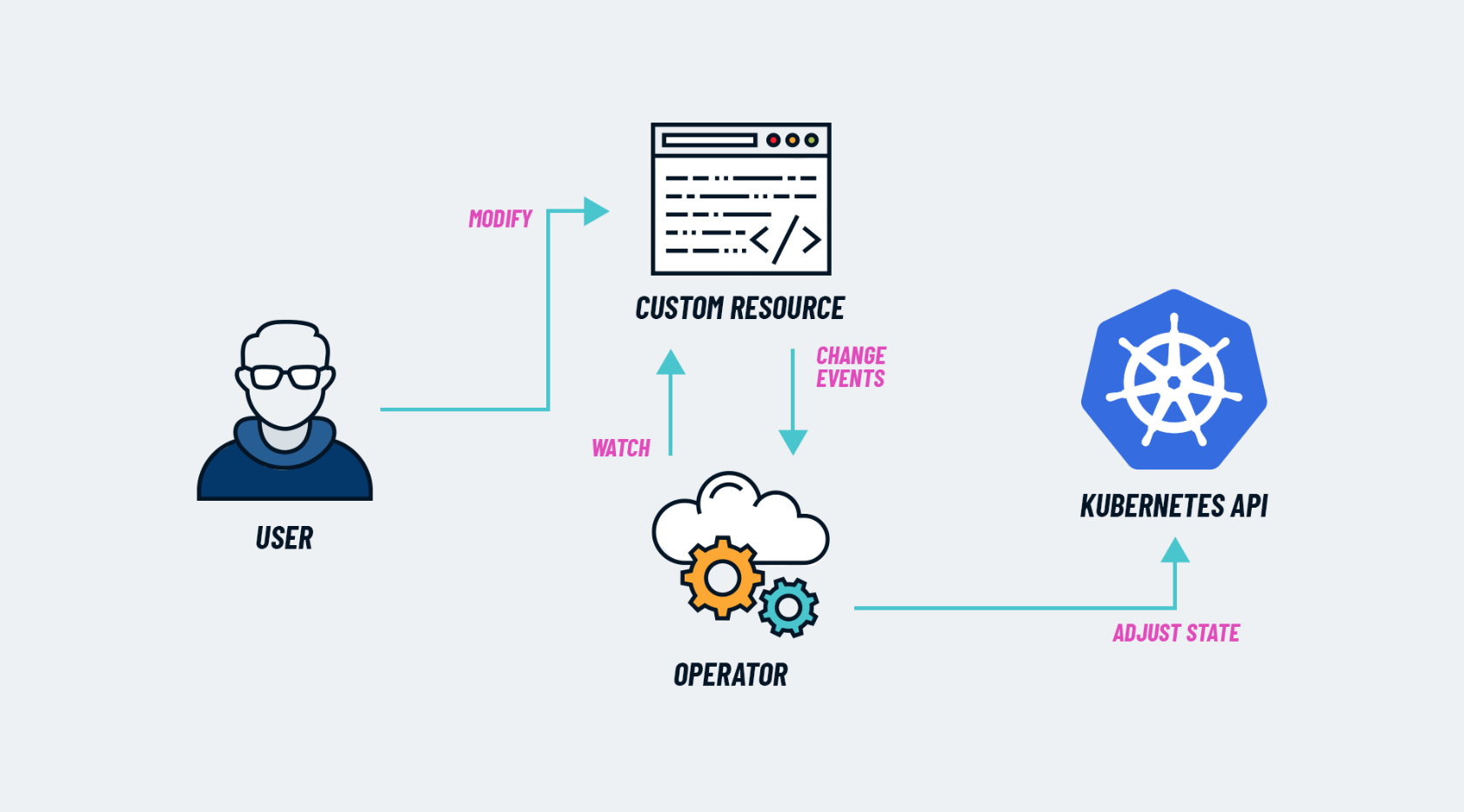
A Kubernetes Operator is a method of packaging, deploying and managing a Kubernetes application. Essentially, an Operator is a custom controller that extends the functionality of the Kubernetes API. This is accomplished by introducing new custom resources or by modifying existing ones.
Kubernetes Operators let you handle complex applications more easily.Operators are designed to handle tasks like upgrades, backups and failover in a more automated and reliable way. They can even make complex decisions based on the state of your cluster.
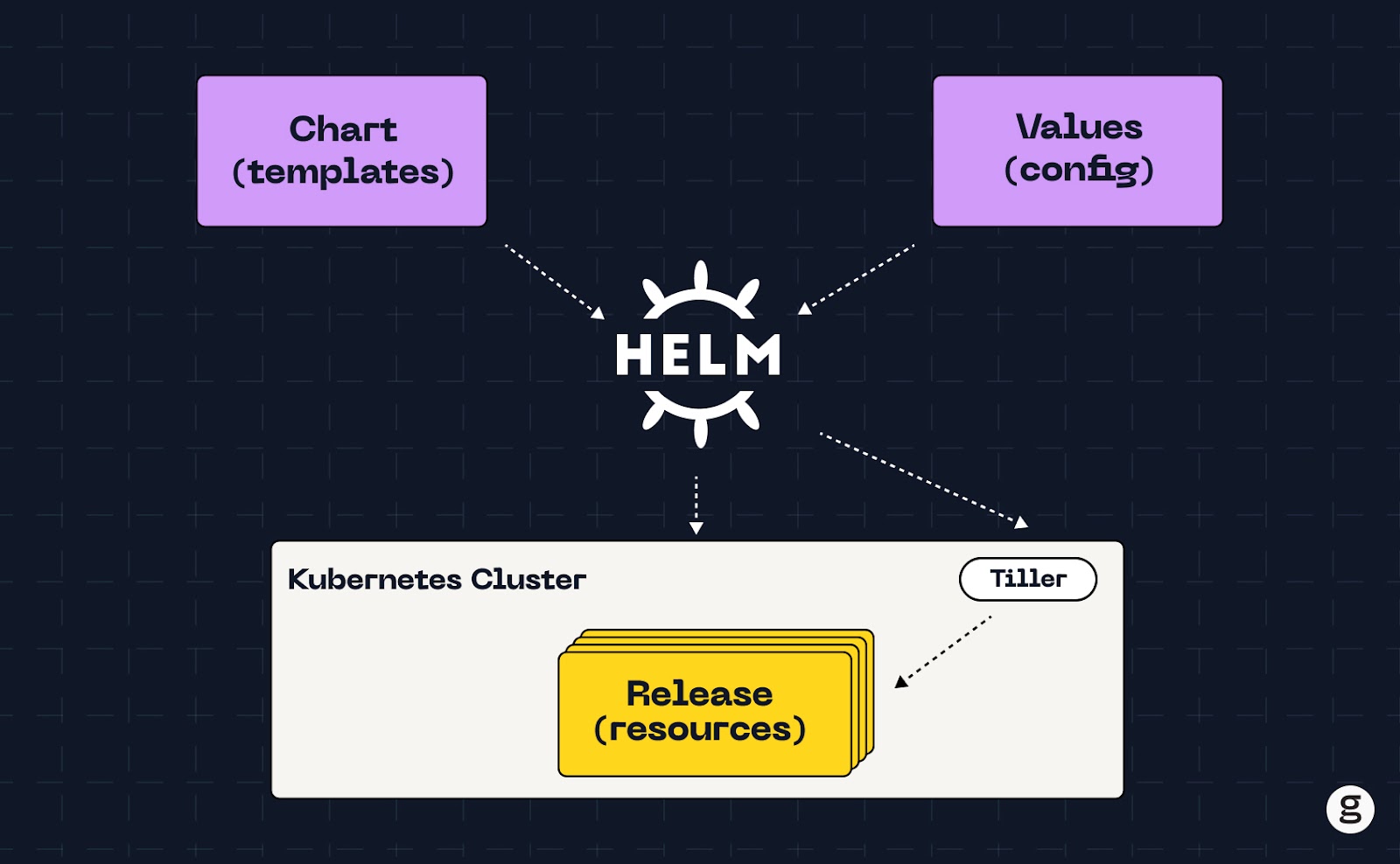
A Helm chart is a package that contains the resources necessary for deploying an application on Kubernetes using a packaging format called charts. You can install Helm charts with (you guessed it!) Helm, an application package manager and configuration management tool for Kubernetes.
Which one to choose
If you need to manage complex, stateful applications and require a high degree of automation, Kubernetes Operator may be the better choice. On the other hand, if you’re looking for a simpler tool to help with application deployment or if you’re new to Kubernetes, Helm may be a more suitable option.
Vanilla Kubernetes vs Distribution Kubernetes
Vanilla Kubernetes is the upstream version of Kubernetes that is maintained by the Kubernetes community. It is the most basic and pure form of Kubernetes, without any modifications or additions. Vanilla Kubernetes is also known as stock Kubernetes or plain Kubernetes.
👍Pros
- Flexible: highly flexible and customizable, allowing users to create and deploy a wide range of applications and workloads
- Cost-effective: free and open-source, which means that users do not have to pay for support or maintenance fees
👎Cons
- Steep learning curve: can be difficult to learn and use, especially for users who are new to container orchestration
- Complex deployment and management: deploying and managing vanilla Kubernetes requires more technical expertise and manual configuration
Distribution Kubernetes
A Kubernetes distribution is a packaged version of Kubernetes that includes additional features, tools, integrations, and support. A Kubernetes distribution aims to simplify the installation, configuration, management, and operation of Kubernetes clusters.
🔴Types of Kubernetes Distributions
Enterprise Kubernetes: designed for large enterprises and offer additional features such as advanced security, scalability, and manageability. Examples of enterprise Kubernetes distributions include Red Hat OpenShift, IBM Cloud Kubernetes Service, and Google Kubernetes Engine (GKE)Community Kubernetes: designed for the open-source community and offer a range of features and tools that are not available in Vanilla Kubernetes. Examples of community Kubernetes distributions include CoreOS, Fedora, and openSUSECloud-Native Kubernetes: designed for cloud-native applications and offer additional features such as serverless computing, service mesh, and observability. Examples of cloud-native Kubernetes distributions include AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), and Google Kubernetes Engine (GKE)Hybrid Kubernetes: designed for organizations that need to run Kubernetes on-premises and in the cloud. Examples of hybrid Kubernetes distributions include VMware Tanzu, OpenStack, and Kubernetes on AWS
👍Pros
- Easier to use: provide a more streamlined and simplified experience for users, with additional tools and features that make it easier to deploy and manage applications
- Additional features: offer additional features and capabilities, such as advanced security, scalability, and manageability
- Support and maintenance: typically supported and maintained by the vendor, which means that users can receive support and updates more quickly and easily
- Integration with other tools: integrate with other tools and services, such as monitoring, logging, and security solutions, which can simplify the deployment and management of applications
- Security and compliance: some distributions come with built-in security features and compliance controls, making it easier for organizations to meet industry regulations and protect their applications and data
👎Cons
- Less flexible: they are designed to meet specific needs and use cases. This can limit the range of applications and workloads that can be deployed
- Vendor lock-in: can lead to vendor lock-in, as users may become dependent on the vendor’s tools and features
Additional cost: often come with additional costs, such as support and maintenance fees, which can add to the overall cost of using Kubernetes