c-language-tips
Overview
parameter passing
x86 always uses stack to pass function parameter, while x86-64 always uses registers to pass function if possible(as it has more registers than x86)
ESP (Extended Stack Pointer), always points to the top of the stack. RSP(x86-64)EBP (Extended Stack Base pointer), like a stack boundary for a function, all stack variables are offset from it.RBP(x86-64), EBP bottom of stack which has the highest address.push
- decrease ESP(get a slot), save value to stack(slot, 4 bytes or 8 bytes etc)
pop
- get the value, increase ESP
stack change when call a function on x86-64
1 |
|
On x86-64, arguments passed into foobar() use registers, while local variables of that function, along with some other data, are going to be stored on the stack when foobar is called. This set of data on the stack is called a frame for this function.
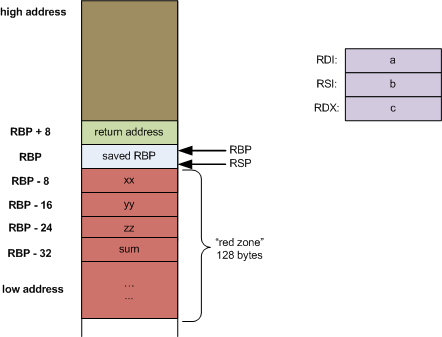
- push IP into stack(called by CPU at runtime,
you can not see this in assembly) - push rbp(parent) into stack
- set rbp with rsp
- pass parameter into register
after call foobar
- push local variable into stack
- calculate
- pop rbp
- pop IP
Note: One process just has one stack, not each for a function, but xx,yy,zz location may be different based on complier or os arch, before calling a function, CPU will put the next ins(IP) onto stack.
x86-64 assembly
1 | 4:a.c **** int foobar(int a, int b, int c) |
function vs macro
Both are used to replace similar code that are always used in different places, macro makes writing code simple and easy to read, but the assembly code is not reduced after used macro while function has the same advantages as Macro does, and the assembly code is small, takes small disk space and small memory when loaded after used function. but the disadvantages is that calling a function takes some time if it's not a inline function. below are some general rules to obey when use function or macro.
rules to obey
large similar use function
here I say similar not same, same code is easy to define a function, but similar code may have some trouble, similar code here the logical process is same, but the variable may be different TYPE, as function parameter only has one TYPE, so it’s not easy for this case, the solution for this is to
abstract the same part for each of TYPE, access the same part of it in the function, if TYPES have no same parts(members), define each of a tinny function(different part depends on type)(void*) for each of the TYPE, call the tinny function in the common function, so that common function(with void*) can replace the 'similar code'and easy to read and extend for new TYPES.
1 | // A and B function have the same logical but only small part is different. |
- small similar code two choices depending on the code
- similar code accesses the
same type of variable, use inline function(can use macro as well), - similar code accessed the
different types of variablesuse Macro
- similar code accesses the
tips for using macro
you can pass parameter from one macro to another.
# used to get the
stringof “passed_value”in the body##used to link parameter with other
in the bodyyou can
NOT use # and ## during parameter passing, there is no effectdo
NOT define variable inside macrowhileused outside of itmacro is only effect from the beginning to the end of that file, but if you define it in *.h, as you know *.h will be copied to the file(*.c) who includes it
difference between ## and # in macro
1 | // '#' used to get the string of the parameter, you can pass hello without "" but #msg return the value of "hello" !!! |
msg: hello
msg: “hello”
1 | file: a.c |
1 | root@dev:/tmp# gcc -o t a.c |
ifdef/if vs macro
macro and ifdef are executed before compiling(**precompile**) but macro is more earlier than ifdef, so first taking replacement with macro, then ifdef.
- how to identify a token(token separated by whitespace) that will be replaced by macro.
- function name
- parameter
- lvalue/rvalue
if Token is equal(same with macro parameter) with macro, replace it with macro!!!
1 |
|
- what can be used as a condition in
ifdef
literal object(integer operation), number 12 or char ‘H’ , if you use variable, its evaluation is always 0
1 |
|
Free memory when process exits
It depends on the operating system. The majority of modern (and all major) operating systems will free memory when process ends.
But relying on this is bad practice and it is better free it explicitly. The issue isn’t just that your code looks bad. You may decide you want to integrate your small program into a larger, long running one. Then a while later you have to spend hours tracking down memory leaks.
Relying on a feature of an operating system also makes the code less portable.
Even if your OS (not all do that) frees memory at exit, there are some reasons to free it explicitly.
- it’s good manner
- it adds symmetry, so code looks better
- if someone takes this code and place it in a program that uses the libraries only in a small part of his runtime, the resources should be free when not needed.
- if you are looking for bad memory leaks, your debugger won’t find these unimportant ones.
- OS does not automatically free some resources at exit, like devices (sensors, scanners…), temporary files,
shared memory.
Send file descriptor to another process
File descriptor can be sent only by AF_LOCAL or AF_UNIX, as during sending, Actually the fd number is not transmitted(it's local for that process), but file descriptor instance(file struct in kernel) is transmitted in skb(scm data), so that receiver can add the transfered file descriptor instance to its process with new fd in its scope, so that after transmission, the file descriptor can be accessed by sender and receiver, actually both linked to it, in most case, the sender will close the fd at its side, hence only receiver accessed that file descriptor.
Steps to take
- Giving SOL_SOCKET to cmsg_level of a struct cmsghdr
- Giving SCM_RIGHTS to cmsg_type of the struct cmsghdr
- Placing the file descriptor at last of the struct cmsghdr
- Assigning the struct cmsghdr to msg_control of a struct msghdr
- Passing the struct msghdr to sendmsg(2) with the Unix domain socket
Using CMSG_DATA is easy to get a pointer to last of the struct cmsghdr for 3
Client
1 |
|
Server
1 |
|
IPC
- Pipe, socketpair, socket(AF_LOCAL)
- signal, eventfd
- shared memory, file, need lock
pipe
Only for parent process—->child process(can be used by different processes as well by send one fd to process), it’s stream-oriented
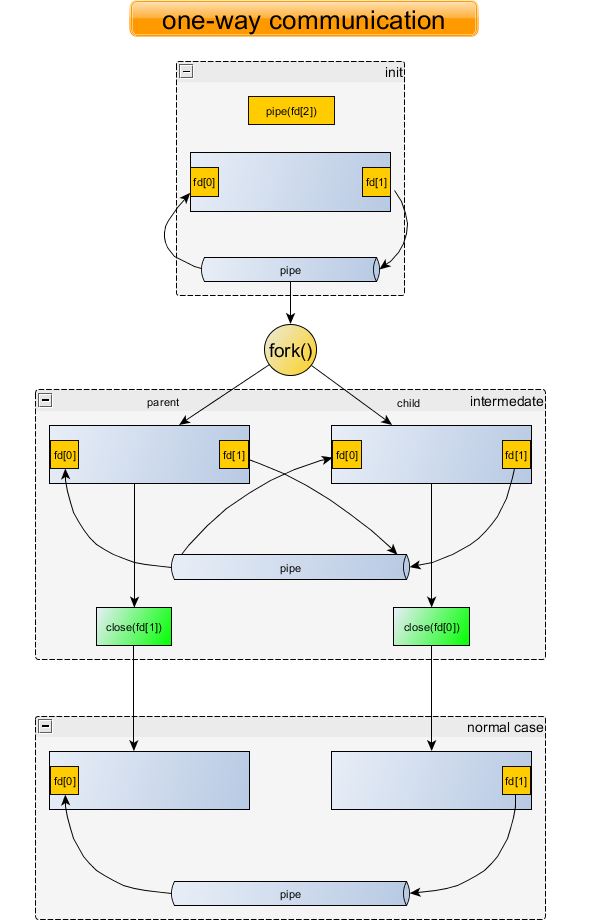
It’s a one-way communication mechanism, with one end opened for reading(fd[0]) and the other end for writing(fd[1]). Therefore, parent and child need to agree on which way to use the pipe, from parent to child or the other way around. A pipe is also a stream communication mechanism, that is all messages sent through the pipe are placed in order,when readers asks for a certain number of bytes from this stream, he is given as many as bytes as are available, up to the amount of request, Note that these bytes may have come from the same call to write() or from several calls to write() which are concatenated.
socketpair
Only for parent process<—->child process, it can be stream or datagram
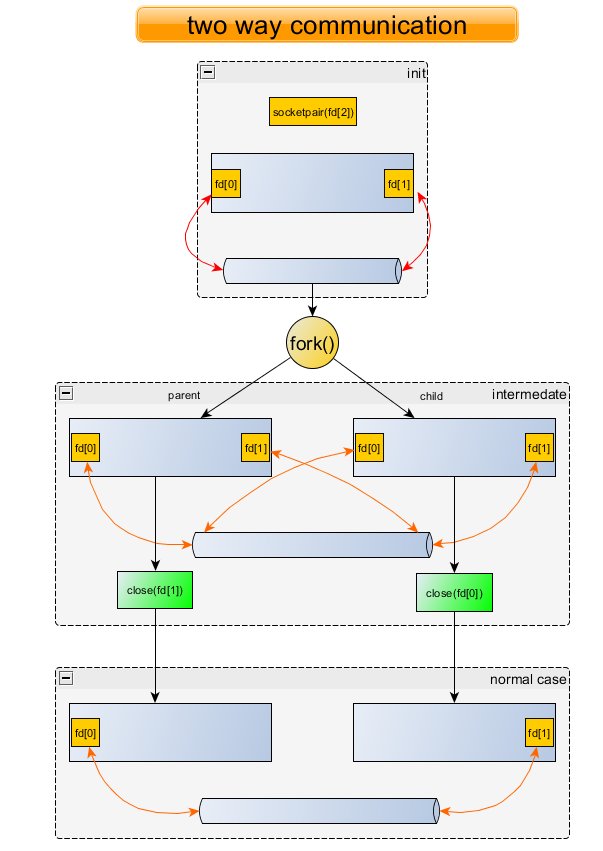
Two-way communication mechanism, an extension of pipe.
named pipe
any process<—->any process
int mkfifo(const char *pathname, mode_t mode)
A FIFO special file is similar to a pipe, except that it is created in a different way. Instead of being an anonymous communications channel, a FIFO special file is entered into the filesystem by calling mkfifo().make sure delete it by your application(call remove() in your application, otherwise it’s left on system
One side
1 | void main() |
the other
1 | void main() |
Two-way communication mechanism.
AF_LOCAL(AF_UNIX) socket
any process<—->any process
Unix domain allows communication between any two processes that are in same machine.
signal
any process<—->any process within same machine
1 | # send signal to process with kill() API |
tiny, only signal number sent, can not take payload
eventfd
it’s fd but used for event counter, parent<—->child
between threads or between process to notify something happens by write a counter into kernel and walkup the reader to handle things.
1 | uint64_t u; |
tiny, can only take integer payload
share memory
Any process<—>any process on same machine, most of time a lock is needed.
system-v style
it uses key to identify the named shared memory, so that other process can access the shared memory, but can also without key for private memory for parent/child, as the shared memory is created before fork(), so both see it.
1 | //one process |
- Private share memory parent/child
shmget() with IPC_PRIVATE as the key
IPC_PRIVATE isn't a flag field but a key_t type. If this special value is used for key, the system call ignores everything but the least significant 9 bits of shmflg and creates a new shared memory segment (on success). The name choice IPC_PRIVATE was perhaps unfortunate, IPC_NEW would more clearly show its function. Both child and parent see the same memory, they always use same memory!!!
posix style
Intend to share memory between unrelated processes. One process creates the file, then other process opens it and maps it for sharing (think it as a normal file, actually it's an identifier of memory)
it uses special file to identify the share memory located at /dev/shm
1 | //one process |
As shm_open() creates a file descriptor, so user must call shm_unlink() to close it(close fd, decrease the reference counter)
Warning
if process does not call shm_unlink, when fd is closed, reference count is not decreased!!! so the shared memory may be never freed at all.
- share memory between parent/child
without shm_open(), use MAP_ANONYMOUS flag and fd(-1) as parent/child all know the shared memory
1 | //before fork() |
- for mmap() with MAP_PRIVATE
Create a private copy-on-write mapping. Updates to the mapping are not visible to other processes mapping the same file, and are not carried through to the underlying file. It is unspecified whether changes made to the file after the mmap() call are visible in the mapped region
That means each process has its own copy of it if it writes to shared memory, other process does not see changed part!!!!
Multiplexing
The poll() API performs the similar API as the existing select() API. The only difference between these two APIs is the interface provided to the caller.
The select() API requires that the application pass in a set of bits in which one bit is used to represent each descriptor number(for example if we only create a socket with fd 1000, the first argument for select is 1000+1, and kernel will create 1001 structure in kernel and unnecessary loop!!!, even if we only create one socket). When descriptor numbers are very large, it can overflow the 30KB allocated memory size, forcing multiple iterations of the process. This overhead can adversely affect performance.
The poll() API allows the application to pass an array of structures rather than a set of bits. Because each pollfd structure can contain up to 8 bytes, the application only needs to pass one structure for each descriptor (we created), even if descriptor numbers are very large.
Both poll() and select() require the full list of file descriptors to watch on each invocation. The kernel must then walk the list of each file descriptor to be monitored. When this list grows large, it may contain hundreds or even thousands of file descriptors walking the list on each invocation becomes a scalability bottleneck.
selectneeds to set monitor fd for each callselectlimits fd number 1024, not true forpolleven with one fd=1000,
selecthas to iterate from 0–1000 times, not true forpollpollneeds set monitor fd only once!!pollno limits fd numberif only with one fd=1000,
polliterates only once, itonly iterates all the monitored fd to see if it has event.
epoll circumvents this problem by decoupling the monitor registration from the actual monitoring. One system call initializes an epoll context, another adds monitored file descriptors to or removes them from the context, and a third performs the actual event wait.
epollneeds set monitor fd only once!!epollno limits fd number- it only
iterates the monitored fd which has event, fast.
select
One API: select()
1 | select(fdmax+1, &read_fds, NULL, NULL, NULL) |
For each loop
- tell the
max fd and fds that monitors - if event happens, check
all from 0--maxto know event on which fd(both in kernel and user)
The major disadvantages include:
select
modifies the passed fd_sets so none of them can be reused. Even if you don’t need to change anything, such as if one of descriptors received data and needs to receive more data, a whole set has to be either recreated again or restored from a backup copy via FD_COPY. Andthis has to be done each time the select is called.To find out which descriptors raised the events you have to manually
iterate through all the descriptors in the set and call FD_ISSET on each one of them. When you have 2,000 of those descriptors and only one of them is active, likely, the last one, you’re wasting CPU cycles each time you wait.Max number of supported fd 1024, Did I just mention 2,000 descriptors? Well, select cannot support that much. At least on Linux. The maximum number of the supported descriptors is defined by the FD_SETSIZE constant, which Linux happily defines as 1024. And while some operating systems allow you to hack this restriction by redefining the FD_SETSIZE before including the sys/select.h, this is not portable. Indeed, Linux would just ignore this hack and the limit will stay the same.Can not close fd if it's in select() now, You cannot modify the descriptor set from a different thread while waiting. Suppose a thread is executing the code above. Now suppose you have a housekeeping thread which decided that sock1 has been waiting too long for the input data, and it is time to cut the cord. Since this socket could be reused to serve another paying working client, the housekeeping thread wants to close the socket. However the socket is in the fd_set which select is waiting for. Now what happens when this socket is closed? man select has the answer, and you won’t like it. The answer is, “If a file descriptor being monitored by select() is closed in another thread, the result is unspecified”.Can't send data on fd if it's in select() nowSame problem arises if another thread suddenly decides to send something via sock1. It is not possible to start monitoring the socket for the output event until select returns.select puts extra burden on you when filling up the descriptor list to calculate the largest descriptor number and provide it as a function parameter.
is there is any reason to use select at all?
The first reason is
portability. select has been around for ages, and you can be sure that every single platform around which has network support and nonblocking sockets will have a working select implementation while it might not have poll at all. And unfortunately I’m not talking about the tubes and ENIAC here; poll is only available on Windows Vista and above which includes Windows XP – still used by the whooping 34% of users as of Sep 2013 despite the Microsoft pressure. Another option would be to still use poll on those platforms and emulate it with select on those which do not have it; it is up to you whether you consider it reasonable investment.The second reason is more exotic, and is related to the fact that select can – theoretically –
handle the timeouts with in the one nanosecond precision, while both poll and epoll can only handle the one millisecond precision. This is not likely to be a concern on a desktop or server system, which clocks doesn’t even run with such precision, but it may be necessary on a realtime embedded platform while interacting with some hardware components. Such as lowering control rods to shut down a nuclear reactor – in this case, please, use select to make sure we’re all stay safe!
The case above would probably be the only case where you would have to use select and could not use anything else. However if you are writing an application which would never have to handle more than a handful of sockets (like, 200), the difference between using poll and select would not be based on performance, but more on personal preference or other factors.
poll
One API: poll()
1 | poll(ufds, 2, 3500); |
For each loop
- tell
only the fds monitorsnot max fd as select does. - if event happens, check
all monitorsto see event on which fd(both in kernel and user), iterate all and compare to find th
e fd that has events.
poll was mainly created to fix the pending problems select had, so it has the following advantages over it:
There is no
hard limit on the number of descriptors poll can monitor, so the limit of 1024 does not apply here.It does not modify the data passed in the struct pollfd data. Therefore it could be
reused between the poll() callsas long as set to zero the revents member for those descriptors which generated the events. The IEEE specification states that “In each pollfd structure, poll() shall clear the revents member, except that where the application requested a report on a condition by setting one of the bits of events listed above, poll() shall set the corresponding bit in revents if the requested condition is true“. However in my experience at least one platform did not follow this recommendation, and man 2 poll on Linux does not make such guarantee either (man 3p poll does though).It allows more fine-grained control of events comparing to select. For example, it can
detect remote peer shutdown without monitoring for read events.
poll still has a few issues which need to be kept in mind:
Like select, it is still not possible to find out which descriptors have the events triggered without
iterating through the whole list and checking the revents. Worse, the same happens in the kernel space as well, as the kernel has to iterate through the list of file descriptors to find out which sockets are monitored, and iterate through the whole list again to set up the events.Like select, it is
not possible to dynamically modify the set or close the socket which is being polled
poll should be your preferred method even over epoll if the following is true:
You need to support more than just Linux, and do not want to use
epoll wrappers such as libevent(epoll is Linux only);Your application needs to monitor
less than 1000 sockets at a time(you are not likely to see any benefits from using epoll);Your application needs to monitor more than 1000 sockets at a time, but the
connections are very short-lived(this is a close case, but most likely in this scenario you are not likely to see any benefits from using epoll because the speedup in event waiting would be wasted on adding those new descriptors into the set – see below)Your application is not designed the way that it changes the events while another thread is waiting for them (i.e. you’re not porting an app using kqueue or IO Completion Ports).
epoll

Two APIs: epoll_ctl() and epoll_wait()
For each loop
no need to tell fds monitors as kernel keeps it from another API- if event happens,
no need to checkto see event on which fd, asepoll() returns only the fd that has events.
epoll has some significant advantages over select/poll both in terms of performance and functionality:
epoll returns only the list of descriptors which triggered the events.
No need to iterate through 10,000 descriptors anymore to find that one which triggered the event!You can
attach meaningful context to the monitored eventinstead of socket file descriptors. In our example we attached the class pointers which could be called directly, saving you another lookup.You can
add sockets or remove them from monitoring anytime, even if another thread is in the epoll_wait function. You can even modify the descriptor events. Everything will work properly, and this behavior is supported and documented. This gives you much more flexibility in implementation.Since the kernel knows all the monitoring descriptors, it can
register the events happening on them even when nobody is calling epoll_wait. This allows implementing interesting features such as edge triggeringIt is possible to have the
multiple threads waiting on the same epoll queue with epoll_wait(), something you cannot do with select/poll. In fact it is not only possible with epoll, but the recommended method in the edge triggering mode.
epoll is not a “better poll”, and it also has disadvantages when comparing to poll:
Changing the event flags(i.e. from READ to WRITE) requires the epoll_ctl syscall, while when using poll this is a simple bitmask operation done entirely in userspace. Switching 5,000 sockets from reading to writing with epoll would require 5,000 syscalls and hence context switches (as of 2014 calls to epoll_ctl still could not be batched, and each descriptor must be changed separately), while in poll it would require a single loop over the pollfd structure.Each accepted socket needs to be added to the set, and same as above, with epoll it has to be done by calling epoll_ctl which means there are
two required syscalls per new connection socket instead of one for poll. If your server has manyshort-lived connections which send or receive little traffic, epoll will likely take longer than poll to serve them.epoll is
exclusively Linux domain, and while other platforms have similar mechanisms, they are not exactly the same ,edge triggering, for example, is pretty unique (FreeBSD’s kqueue supports it too though).High performance processing logic is more complex and hence more difficult to debug, especially for edge triggering which is prone to deadlocks if you miss extra read/write.
Therefore you should only use epoll if all following is true:
Your application runs a thread poll which
handles many network connectionsby a handful of threads. You would lose most of epoll benefits in a single-threaded application, and most likely it won’t outperform poll.You expect to have a reasonably
large number of sockets to monitor(at least 1,000); with a smaller number epoll is not likely to have any performance benefits over poll and may actually worse the performance;Your connections are relatively long-lived; as stated above epoll will be slower than poll in a situation when a new connection sends a few bytes of data and immediately disconnects because of extra system call required to add the descriptor into epoll set;
Your app depends on other Linux-specific features (so in case portability question would suddenly pop up, epoll wouldn’t be the only roadblock), or you can provide wrappers for other supported systems. In the last case you should strongly consider libevent.
epoll Triggering modes
epoll provides both edge-triggered and level-triggered modes. In edge-triggered mode, a call to epoll_wait will return only when a new event is enqueued with the epoll object, you should receive all data when event happens, otherwise, next call epoll_wait will block if no new data, while in level-triggered mode, epoll_wait will return as long as the condition holds.
For instance, if a pipe registered with epoll has received data, a call to epoll_wait will return, signaling the presence of data to be read. Suppose, the reader only consumed part of data from the buffer. In level-triggered mode, further calls to epoll_wait will return immediately, as long as the pipe’s buffer contains data to be read. In edge-triggered mode, however, epoll_wait will return only once new data is written to the pipe.
edge-triggered mode must read them all if read event happens
- how do I know all data is read for this time(read event)?
1 | n = recv(fd, buf, buflen) |
Multi-thread
pthread_cleanup_pop and pthread_cleanup_push
As multi-threads share the address namespace, if a resources is shared by multi-thread for writing, a mutex lock is needed for this, something like this in all threads, but in some case one thread may call pthread_cancel() to abort another thread, if that thread just gets lock but did not run unlock, it will be terminated, no chance to run unlock, hence causes other threads waiting on the lock which will never be freed,deadlock. so we can add a callback that will be called even abort signal by pthread_cleanup_pop and pthread_cleanup_push.
1 | pthread_mutex_lock(&mutex); |
pthread_cleanup_push added a callback that will be called even receives abort signal, so we can unlock the mutex in
the callback.
the callback executes in three cases.
- The thread exits (that is, calls pthread_exit()).
- The thread acts upon a cancellation request.
- The thread calls pthread_cleanup_pop() with a non-zero execute argument
1 | // void pthread_cleanup_push(void (*routine)(void*), void *arg); |
pthread_join
In multiple threads, one thread may depend on another thread, for instance, A must execute after B quits, or before A quits we must quit B firstly, that’s why pthread_join(wait another thread exits, blocked caller) comes in. one typical case:
In main thread, we create a new thread, if no pthread_join, the two threads may run across, if main thread quits before the new thread (new thread still some work to do), the left work can’t be done, because when the main thread quits, all resources will be freed by OS, the new thread will exit as well!
1 |
|
thread-safe vs multi-safe vs signal-safe
lockless queue/stack
In order to achieve lockless, there are two main points.
- use
CMPXCHG(x86)directiveatomic operation - optimize your code and data structure, to
compress your code to access critical area in one statementorcheck and set flags in one ins, then access critical areato block from user level.
what does CMPXCHG do
1 | //simulate it in C code |
Thanks to gcc, we no need to write assembly code to do it, as it provides us two functions with written in assembly(CMPXCHG)
GCC built-in
1 | bool __sync_bool_compare_and_swap (type *ptr, type oldval, type newval, ...) |
lockless stack
1 | struct node { |
glibc pthread mutex Semaphores and futex
Before introduce futex(fast userspace mutex), let’s see how pthread_mutex implement in earlier days, when you call pthread_mutex_lock(), it calls another sytem call whick will do below things in kernel.
- check if the lock available
- if unavailable, sleep the caller.
what’s the problem with such solution? let’s say if the lock is not used frequently, we still need to go to kernel to check and get the lock. but for check and get the lock we can move it to user space, so that if lock is not used highly, we do not need to go to kernel as no need to sleep the process which must be done by kernel. this is the core concept that futex does, futex includes two parts one part is in glibc that checks the lock, the other part is in kernel when lock not available, call a system api(futex()) to sleep the caller, futex can also wake a process based on parameter
1 | //futex 的逻辑可以用如下C语言表示 |
futex(uaddr, FUTEX_WAKE, 1)
futex(uaddr, FUTEX_WAIT, 1)
From kernel 2.5.7(2002), glic uses futex to implement pthread_mutex and semaphores, pthread_join() also calls futex to sleep the caller
get thread id
1 |
|
condition
Condition used like this
1 | //thread 1: |
Multi-process
wait() vs waitpid()
Always call wait in parent process, otherwise child process will never die(destroyed by os), without wait() call, exited child is in zombie state, memory is freed, but task struct is not freed.
zombie process
When a process exits, OS frees all memory for it and closes all fds, only left task_struct which has meta data of exited process like process id, exit state, cpu usage etc, then OS sends SIGCHILD to its parent, before parent call wait or waitpid, the exited process is a zombie, if parent never calls wait/waitpid, it’s always zombie, after parent calls wait/waitpid, the only left task_struct is freed.
The wait() system call suspends execution of the current process until one of its children terminates. The call wait(&status) is equivalent to: waitpid(-1, &status, 0), but waitpid support non-block mode if no child exited by setting option.
- WNOHANG return immediately if no child has exited.
The waitpid() system call suspends execution of the current process until a child specified by pid argument has changed state(terminated or stopped).
waitpid(pid, &status, WIFEXITED)
waitpid(pid, &status, WIFSTOPPED)
Always use waitpid() as it’s powerful,it can return when [any one] or ]particular one] or ]no one exited] while wait() always block, wakeup only when any child quits
execve()
exec() familiy executes the program referred to by pathname. This causes the program that is currently being run by the calling process to be replaced with a new program, with newly initialized stack, heap, and (initialized and uninitialized) data segments, except below:
File descriptors open except for those whose close-on-exec flag (FD_CLOEXEC) is set- Process ID
- Parent process ID
- Process group ID
- Session membership
- Real user ID
- Real group ID
Current working directory- File mode creation mask
- Process
signalmask - Pending signals
In short
You can think it roughly all are replaced except keeping the file descriptors, signal, pid, uid so make sure close these opened file, there are two ways to do this.
One way
Add flag when open a file(socket) with O_CLOEXEC
The other way
after open, use fcntl() to set a flag FD_CLOEXEC
Mix process and thread, call fork in thread?
Should never call fork in multi-thread as there are lots of non-obvious problems that you can’t detect them easily.
The non-obvious problem in this approach(mix them) is that at the moment of the fork(2) call some threads may be in critical sections of code, doing non-atomic operations protected by mutexes. In the child process the threads just disappears and left data half-modified without any possibility to “fix” them, there is no way to say what other threads were doing and what should be done to make the data consistent. Moreover: state of mutexes is undefined, they might be unusable and the only way to use them in the child is to call pthread_mutex_init() to reset them to a usable state. It’s implementation dependent how mutexes behave after fork(2) was called. On my Linux machine locked mutexes are locked in the child.
malloc, syslog(), printf() use lock internally, be careful with them in multi-thread or multi-process.
More details, refer to think-twice-before-using-tem
pipe vs pipe2 vs socketpair and dup vs dup2
pipe(fd[2])/pipe2(fd[2], flag) create a unidirection channel with two fds(fd[0] for read, while fd[1] for write), pipe2 gives more control when creating the channel like set NON_BLOCK etc.
pipe2() is to avoid race conditions by taking the O_CLOEXEC | O_NONBLOCK, https://man7.org/linux/man-pages/man2/open.2.html
socketpair(domain, proto, fd[2]) is similar to pipe, actually, it's extension of pipe, it's two-way communication.
dup(oldfd)/dup2(oldfd, newfd) make duplicate the fd, hence dup2 lets you provide the new fd while dup() pick the smallest unused fd
dup(oldfd) will duplicate the oldfd, the return value is new fd(dup always pick the smallest fd unused)
dup2(oldfd, newfd) takes two fd, oldfd must be created before dup2, it will use newfd points to oldfd, if newfd is open, it will silently close it before reuse it.
typical use for pipe
parent creates a pipe, then fork child, child/parent use pipe for one-way communication.
1 | int fd[2]; |
typical use for dup/dup2 along with pipe
1 | int fd[2]; |
little-endian and big-endian
“Little Endian” means that the low-order byte of the number is stored in memory at the lowest address, and the high-order byte at the highest address. (The little end comes first.) For example, a 4 byte Int
`Byte3 Byte2 Byte1 Byte0`
will be arranged in memory as follows:
1 | Base Address+0 Byte0 |
Intel processors (those used in PC’s) use “Little Endian” byte order.
“Big Endian” means that the high-order byte of the number is stored in memory at the lowest address, and the low-order byte at the highest address. (The big end comes first.) Our LongInt, would then be stored as:
1 | Base Address+0 Byte3 |
Motorola processors (those used in Mac’s) use “Big Endian” byte order.
daemonize
To daemonize, there are two ways to do it.
- Make itself as daemon
1. parent -> fork (child)
2. parent exit
3. init take orphan child - It’s daemon, want to daemonize its child(forked from me)
1. parent ->fork(child)
2. child -> fork(grandchild)
3. child exit
4. init take orphan grandchild
gcc
gcc provides lots of built-in keywords like inline, typeof etc for better use.
Note: while -ansi and the various -std options disable certain keywords (asm, inline typeof) in such case, use__asm__, __inline__, __typeof__ when -ansi or -std is enable during compiling.
typeof
get type of variable then define internal variable in Macro, this is what ‘typeof’ is always used.
1 | //a and b are two pointers |
inline
GCC does not inline any functions without optimizing(-o0) unless you specify the ‘always_inline’ attribute for the function.
- suggest inline, inline or not determined by compiler
inline void foo() {} - force inline
inline void foo()__attribute__((always_inline)) {}
Note: inline keyword is added at function definition not declaration
What does compiler do if it inlines that function?
Actually for a inline function, compiler will repace the function call with extended code, that means there is no function call happens for inline function, fast but with more code, but there are exceptions here, if we assign inline function to a function pointer, compiler will create function(even it’s inline) for it with an address, otherwise, if this no function in assemble code for inline function.
inline in dot c file
if you define inline function in dot c and want to call it in another dot c, compiler will create a function address for inline function as well, another dot c sees it as a normal function, but in the file it defines, it's a inline. function.
inline in dot h file
if you define it in dot h, as dot h will be copied to the c file who includes it, so that there are several copied of this inline function like it's defined in that dot c file so it's inlined for dot c file.
For short shared function, define it as inline in dot h file with static keyword
static used in header
One important thing that must know is that for header file it will be copied to dot c file who includes it. that means if you static int b = 12 in a header file, if it’s included by two dot c files, it has the same effect that two dot c files define static int b = 12 for themself.
1 | //File q7a.h: |
1 | gcc –Wall –c q7a.c –o q7a.o |
attribute of function
__attribute__ can be used only in declaration! here only list common attributes that may be used in your daily life.
- deprecated: indicate you’d better not use me as I’m deprecated, if used, warning will appear/
- constructor: run before main
- destructor: run after main
- section: specify the section that I’m defined
- warn_unused_result: warning if result is not used
- noinline: prevent me from being considered for inlining.
- always_inline: force inline
- ununsed: prevent printing warning if not used.
void fun() __attribute__((deprecated));
attribute of variable
- aligned: This attribute specifies a
minimum alignment for the variable or structure field, measured in bytes, if type default alignment is large than this value, use default. alignment=max(default, aligned)
Whenever you leave out the alignment factor in an aligned attribute specification, the compiler automatically sets the alignment for the declared variable or field to the largest alignment which is ever used for any data type on the target machine you are compiling for. Doing this can often make copy operations more efficient, because the compiler can use whatever instructions copy the biggest chunks of memory when performing copies to or from the variables or fields that you have aligned this way.
Thealigned attribute can only increase the alignment; but you can decrease it by specifying packed as well
- packed: The packed attribute specifies that a variable or structure field should
have the smallest possible alignment–one byte for a variable, and one bit for a field, alignment=min(default, packed) - deprecated: see function
- section: see function
- unused: see function
attribute of type
- aligned: same as variable
- packed: specifying this attribute for struct and union types is
equivalent to specifying the packed attribute on each of the structure or union members
1 | struct T1{ |
- deprecated: see variable.
typedef int T1 __attribute__((deprecated));
built-in function
- the most/less significant bit
1 |
|
tips
should add void to function parameter who has no parameter?
Yes, it’s better do that as if compiling with -Werror=strict-prototypes, it will show error if function did not add void to function that does not need parameter.
void hello(void);
Eliminate unused warning
In some case, you do not want to comment unsed variable out , but avoid compiling warning, or avoid warning for unused return value.
(void)unsed_var;(void)function();
use do{}while(0) if want to use block(var) in macro
1 | // group macro in block with do/while, limit var scope if defined in macro |
dynamic argument in macro
When the macro is invoked, all the tokens in its argument list […], including any commas, become the variable argument. This sequence of tokens replaces the identifier VA_ARGS in the macro body wherever it appears.
1 |
|
see assembly with source code
gcc -c -g -Wa,-a,-ad a.c > test.lst
show convertion warning when compile code
gcc -Wconversion
cacheline aligned
In some case, we want a variable(struct) cache line aligned, so that CPU can read them once(cpu read memory cache line every time), so it’s better put related field(if access a, will access b soon, a, b are related) together in a cache line, check struct layout with pahole
1 | # install it from rpm or from source with below link |
Two typical cache line size: 32 bytes or 64 bytes.
1 | # get cache line size of given cpu |
bit shift
Most of time, bit shift for unsigned integer.
left shift: always pad with 0
right shift:
- unsigned operator, padding with 0
- signed operator, padding with flag bit(for positive 0, 1 for negative)
send/recv API differences
pairs of API for sending /recving data.
'connected' socket can be [STREAM, DGGRAM who called connect()]
- read/readv: read one buffer/several buffers on fd
[file like API] - write/writev: write with one buffer/several on ‘connected fd
[file like API] - recv/send: with one buffer on ‘connected’ socket
- recvfrom/sendto: with on buffer on ‘unconnected’ socket
- recvmsg/sendmsg: with several buffers on ‘connected’ socket
In the kernel side, all mapped to sendmsg and recvmsg of kernel version.
STREAM vs Datagram
Stream communication implies several things, communication takes place across a connection between two sockets, the communication is reliable, error-free, and no message boundaries are kept, reading from a stream may result in reading the data sent from one or several calls to write() or only part of the data from single call, if there is not enough room for the entire message, or if not all data from a large message has been transferred, the protocol implementing such a style will retransmit message received with errors, it will also return error if one tries to send a message after the connection has been broken.
Datagram communication doesn’t use connection, each message is addressed individually, if the address is correct, it will generally be received, although this is not guaranteed, the individual datagram will be kept separate when they are read, that is message boundaries(from user level not from kernel level) are preserved.
1 | TCP-----byte--------stream-----send receive---------------------in order --- -------------may partial |
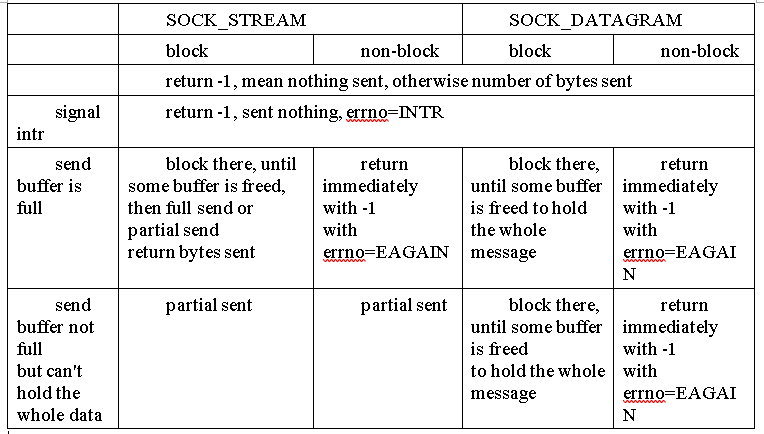
when call sendto(), there are two limitation, one is the socket sendbufer, the other is
MAX_MESSAGE_SIZE(udp payload)==65507==65535(max ip length)-20(ip header)-8(udp header) but ip packet will may be fragment due to MTU(1500), so you can send max udp message(not include udp header) is 65507, fragment always happens at IP layer for UDP if possible(not happend when GSO is enabled, in that case, IP fragment happens when sending to driver after go through network stack), but for TCP, there is no IP fragment at sender machine as TCP already split into smaller message before call IP layer(GSO/TSO is another case), but if socket send buffer is not enough to hold it, sendto() will blocked until kernel send some message and free the room.
TCP bi-direction
For a tcp connection, it’s bi-direction, that means both sides can send and recv data from the other, but you can close one direction, to make one side as reader, the other side as writer only. shutdown() allows you to only stop data transmission in a certain direction, while data transmission in one direction continues. If you can close the write operation of a socket and allow to continue to accept data on the socket until all data is read.
More control about TCP close
1 | int shutdown (int sockfd, int how); |
add a wrapper for a function who defined in dynamic library
this is used when need to add a wrapper for a function that’s defined in dynamic library(so that you don’t see the source code of it!!) like C dynamic library or other dynamic library (dynamic library!!!!!!!!)
step 1: create you own dynamic library
1.1 program wrapper library
void* malloc(size_t size)
{
void ret;
static void (realmalloc(size_t size)) = NULL;
if (realmalloc == NULL) {
realmalloc = dlsym(RTLD_NEXT, “malloc”); / function that will be wrapped
}
ret = realmalloc(size);
!!!!add trace here!!!!!!!!!!!!
return ret;
}
1.2 compile it into wrapper.sostep 2: create your program like before, see nothing happens
ptr = malloc(64);setp 2: load it, must load your dynamic library before any other dynamic libray!!!
LD_PRLOAD=./wrapper.so ./program
(wrapper.so is your dynamic library that wrapps
the dynamic library(like C dynamic library)
NULL vs 0
when evaluate the value of NULL, it’s 0, but if you assign NULL to non-pointer, it's a warning, but a has value 0!
1 | int a = NULL? 1: 2; //now a is 2!!! |
function pointer
1 | void hello(void(*h)()) |
sizeof vs strlen
strlen returns memory byte size when it sees '\0' while sizeof calculates the size of bytes that the variable takes.
1 | char *p = "a"; //sizeof(p)==8 (x86-64), strlen(p)==1 |
1 | // char *p and char p[] behave same when used in parameter. |
what about char p[0] in a struct
1 | struct prot { |
what about function in a struct
1 | struct prot { |
shared variable between source(global variable)
- define it at xxx.c
int global_v = 10;
- export it at xxx.h others can include such header, like
other x.c written with extern int global_v as well.extern int global_v;
Can we return a local pointer variable from a function
Actually you should NOT do this, as it’s not a good way as if local pointer points to memory on the stack after function call, it will be freed!!!
1 | char * f1 () |
type length and overflow
1 | char c = 0x40; //64 |
what does volatile really mean
volatile is a keyword to prevent compiler optimizing(like cache value, reorder etc) for the described variable. its value can be changed by code outside the scope of current code at any time. The system always reads the current value of a volatile object from the memory location rather than keeping its value in temporary register at the point it is requested, even if a previous instruction asked for a value from the same object
it may be used to
- describe an object corresponding to a memory-mapped input/output port(driver also does)
- global object accessed by an asynchronously interrupting function(ISR, signal handler), ISR(Signal handler) + Thread
- global object accessed by two threads Thread + Thread
1 | // test.c |
ISR
when ISR always mapps port/io/device register from device exported, we should get its value from memory not cache register as it can be changed by DMA out scope of processor.
how dynamic library is searched when running
Old way, when program starts, it checks below path for dynamic library searching
- directories from LD_LIBRARY_PATH;
- directories from /etc/ld.so.conf(used for additional library)
- /lib64;
- /usr/lib64.
But check path is slow, hence to improve the speed, A cache is used which is located at /etc/ld.so.cache which stores library and its path, fast.
So new way, dynamic library is searched with below
- $LD_LIBRARY_PATH
- /etc/ld.so.cache
ld.so.cache is generated after scanning /etc/ld.conf.conf, /lib64 and /usr/lib64, ldconfig is a tool to do this which is called after each dynamic library is installed by yum/apt.
1 | # if you manually remove or copy a library, you need to rebuild the cache |
how dynamic library is searched when compiling
pkg-config is a tool to check dependencies for a library, it outputs version, header path, libs of that library, so that someone who uses this library passes these to compiler for building.
pkg-config gets all these information by checking xxx.pc from several paths, so that if a library wants to be managed by pkg-config, it must proivde a xxx.pc file at some path.
1 | # get default search paths for pkg-config |