docker-core-tech-ns
Introduction
Namespaces provide processes with their own view of the system, limit what you can see(and therefore use)
Overview
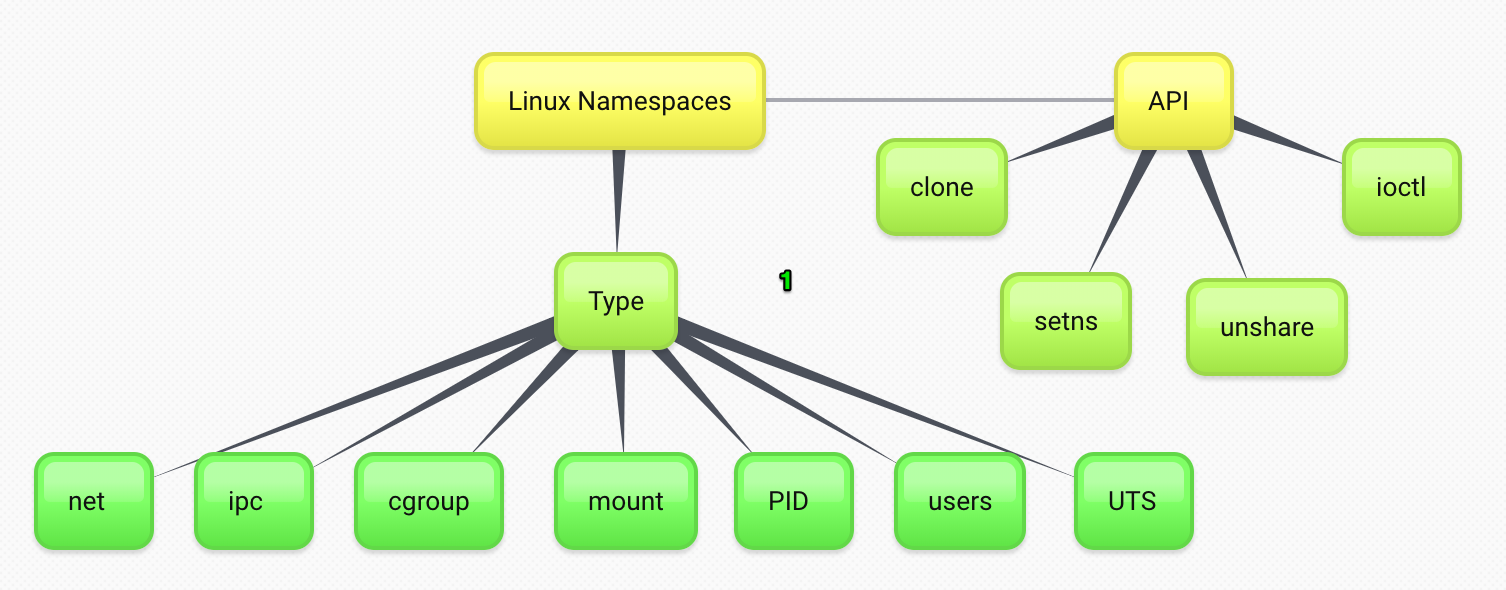
There are multiple namespaces(no cgroup namespace actually):
- pid
each PID namespace has it own numbering(start at 1), when PID 1 goes away, the whole namespace is killed. Even you run process in a PID namespace, root pid namespace still sees it, but the pid number is different in both namespaces, but others non-root pid namespace does NOT see it. - net
processes within a given network namespace get their own private network stack, including:- network interfaces
- routing tables
- iptables rules
- sockets(inet socket, NOT unix socket)
network interface belongs to exactly one net namespace, same for (inet)socket, the newly create net namespace only contains a loopback, no others, when a network space is deleted, all its movable network devices are moved back to the default network namespace, while unmovable devices(device who have NETIF_F_NETNS_LOCAL in their features) and virtual devices are not moved to the default network namespace
- mnt(mount)
processes can have ‘private’ mounts, mounts/unmounts in that mount namespace are invisible to the rest of the system - uts
gethostname/sethostname can be different at uts namespace, you can change hostname in this namespace, but not affect others(namespace) - ipc(rarely used)
Allow a process to have its own- IPC semaphores
- IPC message queues
- IPC shared memory
- user
Allows to map UID/GID(that means you can see mapped uid/gid in user namespace, you can’t know the real pid/gid in container with this mapping)- UID 0-1999 in container C1 is mapped to UID 10000-11999 on host(security improvement)
mount namespace
Mount namespace provides isolation of the list of mounts seen by the processes in each namespace instance. Thus, the processes in each of the mount namespace instances will see distinct single-directory hierarchies.
A new mount namespace is created using either clone(2) or unshare(2) with the CLONE_NEWNS flag. When a new mount namespace is created, its mount list is initialized as follows:
- If the namespace is created using clone(2), the mount list of the child’s namespace is a copy of the mount list in the parent process’s mount namespace.
- If the namespace is created using unshare(2), the mount list of the new namespace is a copy of the mount list in the caller’s previous mount namespace.
Subsequent modifications to the mount list (mount(2) and umount(2)) in either mount namespace will not (if MS_PRIVATE is used[default]) affect the mount list seen in the other namespace, this is controlled by propagation types.
propagation types
MS_SHARED
This mount shares events with members of a peer group(parent process). Mount and unmount events immediately under this mount will propagate to the other mounts that are members of the peer group. Propagation here means that the same mount or unmount will automatically occur under all of the other mounts in the peer group. Conversely, mount and unmount events that take place under peer mounts will propagate to this mount.MS_PRIVATE(default)
This mount is private; it does not have a peer group. Mount and unmount events do not propagate into or out of this mount.MS_SLAVE
Mount and unmount events propagate into this mount from a (master) shared peer group. Mount and unmount events under this mount do not propagate to any peer.
Note that a mount can be the slave of another peer group while at the same time sharing mount and unmount events with a peer group of which it is a member. (More precisely, one peer group can be the slave of another peergroup.)
- MS_UNBINDABLE
This is like a private mount, and in addition this mount can’t be bind mounted. Attempts to bind mount this mount (mount(2) with the MS_BIND flag) will fail.
When a recursive bind mount (mount(2) with the MS_BIND and MS_REC flags) is performed on a directory subtree, any bind mounts within the subtree are automatically pruned
(i.e., not replicated) when replicating that subtree to produce the target subtree.
kernel view
each namespace is identified by an inode(unique), if two processes are in the same namespace if they see the same inode for equivalent namespace types.

FAQ
how to create different namespaces
- namespaces are created with the clone() system call(with extra flags when creating a new process), when the last process of a namespace exits, it’s destroyed automatically by kernel(but can be preserved)
- process can ‘join’ a namespace by setns()
clone flags for namespace
- CLONE_NEWNS
- CLONE_NEWNET
- CLONE_NEWPID
- CLONE_NEWIPC
- CLONE_NEWUTS
- CLONE_NEWUSER
All needs CAP_SYS_ADMIN except CLONE_NEWUSER
how to check namespaces of given process
1 | $ ls -al /proc/$pid/ns |
how to communicate between network namespaces
use veth pair or unix socket
how to check if device is netns local or not
if device with NETIF_F_NETNS_LOCAL, it’s not allowed to move between network namespace; example of this device
- loopback, vxlan, pp, bridge
- use ethtool to check if device is set or not.
1 | $ ethtool -k eth0 | grep local |
how to check mounted point of the system
1 | # this is the real mounts from kernel |
how to run a program in another namespace from shell
There are two commands for this.
unshareto run command innew namespace or existing namespacensenterto run command inanother process's namespace[existing namespace]
1 | unshare [options] <program> [<argument>...] |
network namespace command list
1 | # show all named net ns |