docker-core-tech-cgroups
cgroups
provides a mechanism for aggregating/partitioning sets of tasks, and all their future children, into hierarchical groups with specialized behavior(under resource controller) like- Resource Limiting (i.e. not to exceed a memory limit) mostly used
- Prioritization (i.e. groups may have larger share of CPU)
- Isolation (i.e. isolate GPUs for particular processes)
- Accounting (i.e. monitor resource usage for processes)
- Control (i.e. suspending and resuming processes)
Definitions:
A cgroup associates a set of tasks with a set of parameters(control resource) for one
or more subsystems.A subsystem is a module that makes use of the task grouping
facilities provided by cgroups to treat groups of tasks in
particular ways. A subsystem is typically a “resource controller” that
schedules a resource or applies per-cgroup limits, but it may be
anything that wants to act on a group of processes, e.g. a
virtualization subsystem.A hierarchy is a set of cgroups arranged in a tree, such that
every task in the system is in exactly one of the cgroups in the
hierarchy, and a set of subsystems(CPU, Memory); each subsystem has system-specific
state attached to each cgroup in the hierarchy. Each hierarchy has
an instance of the cgroup virtual filesystem associated with it.
cgroup pseudo filesystem
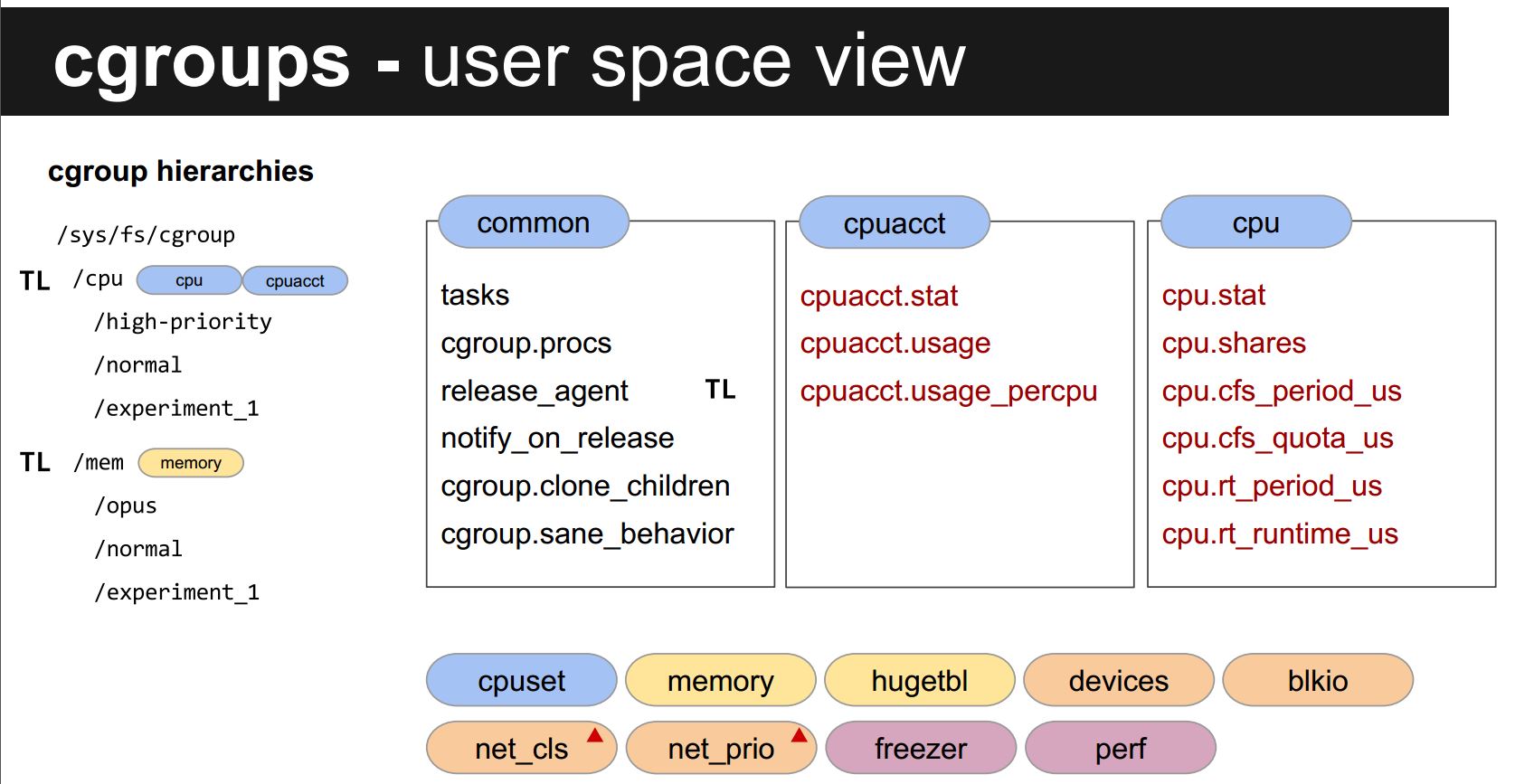
Here are most cgroups(subsys) supported by linux
- cpuset – assigns tasks to individual CPUs and memory nodes in a cgroup
- cpu – schedules CPU access to cgroups(how much cpu used and how long)
- cpuacct – reports CPU resource usage of tasks of a cgroup
- memory – set limits on memory use and reports memory usage for a cgroup, normal page memory not huge page
- hugetlb - allows to use virtual memory pages of large sizes and to enforce resource limits on these pages
- devices – allows or denies access to devices (i.e. gpus) for tasks of a cgroup
- freezer – suspends and resumes tasks in a cgroup
- net_cls – tags network packets in a cgroup to allow network traffic priorities
- blkio – tracks I/O ownership, allowing control of access to block I/O resources
Rules for cgroup
- Each subsystem (memory, CPU…) has a hierarchy (tree)
- Hierarchies are independent
- (the trees for e.g. memory and CPU can be different)
- Each process belongs to exactly 1 node in each hierarchy
- (think of each hierarchy as a different dimension or axis)
- Each hierarchy(subsystem) starts with 1 node (the root)
1 | # like for cpu subsystem root node is at |
- All processes initially belonged to the root of each hierarchy
- Each node = group of processes(sharing the same resources)
NOTE
All subdirs shared the setting of its parent, total amount should not exceed its parent, even tasks in subdir not present in parent’s tasks, see example below.
1 | # NOTE: remove a cgroup dir using: rmdir not rm -rf |
cpu subsystem
sys path: /sys/fs/cgroup/cpu, it’s used for cpu state(usage), weight and limitation for tasks attached to this group, here are several key parameters of this subsystem.
cpu.shares(relative weight to other cpu cgroups)
it’s relative weight to other cgroups under cpu subsystem, when access to host CPU cycles, by default it’s 1024, it works only when other cgroups have tasks attached and competing for host CPU cycles, say cgroupA has task A with default cpu.shares, cgroupB has task B with cpu.shares 2048, if both taskA and taskB are running, taskB get host CPU cycles twice than taskA, while if taskB is slept or quits, taskA will get all host CPU cycles, as no others are competing with it.
As it’s relative weight, It does not guarantee or reserve any specific CPU access.!!!cpu.cfs_period_us
specifies a period of time in microseconds not millisecond(ms) (represented here as “us”) for how regularly a cgroup’s access to CPU resources should be reallocated.
If tasks in a cgroup should be able to access a single CPU for 0.2 seconds out of every 1 second, set cpu.cfs_quota_us to 200000 and cpu.cfs_period_us to 1000000. The upper limit of the cpu.cfs_quota_us parameter is 1 second(1000 milliseconds) and the lower limit is 1000 microseconds(1 milliseconds)cpu.cfs_quota_us and cpu.cfs_period_us(
hard limit for tasks in the group)CPU quota control
how much CPU time tasks in cgroup can use during a period, cpu_quota is the number of microseconds of CPU time, cpu period is counting unit for cpu quota, they should work together to limit the upper bound(max cpu) for that cgroup(tasks in it). by default period is 100000 us, while quota is -1(no limit). if quota is 100000(==cpu period), like tasks in this group can use one host CPU, but if quota is 200000 larger than period, like tasks in this groups can use two Host CPUs.
NOTE
- cgroup controls resource to all tasks in the same group, say for cpu quota and cpu period, counting all tasks for the same cpu use, not per task
- child process forked from task in the cgroup, obey the same limitation with its parent(child task is added parent cgroup automatically)
even quota is two CPU, but if only one task in the cgroup without multi-thread on, at most one CPU is used!!!!
cpu.shares and cpu.cfs_quota_us, cpu.cfs.period_us can work together!!!
host has two cpus, both taskA and taskB are always running, no other task is running for ideal.
- taskA in groupA with share 1024, 1 cpu(cpu.cfs_period_us 100000 cfs_quota_us 100000)
- taskB in groupB with share 2048, 0.5cpu(cpu.cfs_period_us 100000 cfs_quota_us 50000)
- for each period, host provides 2*100000, taskB can get 0.67 due to share setting, but taskB has hard limit 0.5cpu, hence after task B get 0.5cpu, it’s paused, so that taskA continues to run, after one period,
taskA gets 1 cpu, taskB gets 0.5cpu(another 0.5cpu is idea), but taskB gets 0.5cpu before taskA gets its 0.5cpu
warn
- taskA in groupA with share 1024, 1 cpu(cpu.cfs_period_us 100000 cfs_quota_us 100000)
- taskB in groupB with share 1024, 0.5cpu(cpu.cfs_period_us 100000 cfs_quota_us 50000)
- for each period, host provides 2*100000, taskA and taskB gets its 0.5cpu at the same, then taskB paused, taskA continues to run, after one period,
taskA gets 1 cpu, taskB gets 0.5cpu(another 0.5cpu is idea).
docker parameters related
1 | # let's say there are four CPUS on host, if all containers are running CPU intensive workload |
memory subsystem
The memory subsystem generates automatic reports on memory resources used by the tasks in a cgroup, and sets limits on memory use of those tasks.
1 | $ls /sys/fs/cgroup/memory/ |
let’s focus on memory limitation parameters memory.limit_in_bytes, memory.memsw.limit_in_bytes, memory.oom_control, memory.soft_limit_in_bytes, memory.swappiness
memory.limit_in_bytes
sets the maximum amount of user memory (including file cache). If no units are specified, the value is interpreted as bytes. However, it is possible to use suffixes to represent larger units(k/K, m/M, g/G).echo 1G > /cgroup/memory/lab1/memory.limit_in_bytesmemory.memsw.limit_in_bytes
sets the maximum amount forthe sum of memory and swap usage. If no units are specified, the value is interpreted as bytes, However, it is possible to use suffixes to represent larger units(k/K, m/M, g/G).It is important to
set the memory.limit_in_bytes parameter before setting the memory.memsw.limit_in_bytes parameter:, This is because memory.memsw.limit_in_bytes becomes available only after all memory limitations (previously set in memory.limit_in_bytes) are exhausted.memory.limit_in_bytes = 2G and memory.memsw.limit_in_bytes = 4Gfor a certain cgroup will allow processes in that cgroup to allocate 2 GB of memory and, once exhausted, allocate another 2 GB of swap only.memory.soft_limit_in_bytes
enables flexible sharing of memory. Under normal circumstances, control groups are allowed to use as much of the memory as needed, constrained only by their hard limits set with the memory.limit_in_bytes parameter. However, when the system detects memory contention or low memory, control groups are forced to restrict their consumption to their soft limits(reclaim memory).If lowering the memory usage to the soft limit does not solve the contention, cgroups are pushed back as much as possible to make sure that one control group does not starve the others of memory.Note that soft limits take effect over a long period of time, since they involve reclaiming memory for balancing between memory cgroups.memory.oom_control
contains a flag (0 or 1) that enables or disables the Out of Memory killer for a cgroup.If enabled (0), tasks that attempt to consume more memory than they are allowed are immediately killed by the OOM killer. The OOM killer isenabled by defaultin every cgroup using the memory subsystem; to disable it, write 1 to the memory.oom_control file.When the OOM killer is disabled, tasks that attempt to use more memory than
they are allowed are paused until additional memory is freed.memory.swappiness
sets the tendency of the kernel to swap out process memory used by tasks in this cgroup instead of reclaiming pages from the page cache. This is the same tendency, calculated the same way, as set in /proc/sys/vm/swappiness for the system as a whole. The default value is 60.Values lower than 60 decrease the kernel's tendency to swap out process memory, values greater than 60 increase the kernel's tendency to swap out process memory, and valuesgreater than 100 permit the kernel to swap out pages that are part of the address space of the processes in this cgroup.Note that a value of
0 does not prevent process memory being swapped out; swap out might still happen when there is a shortage of system memory because the global virtual memory management logic does not read the cgroup value. To lock pages completely, use mlock() instead of cgroups.NOTE:
Increasing this value will make the system more inclined to utilize swap space,leaving more memory free for caches.
Decreasing this value will make the system less inclined to swap, andmay improve application responsiveness.Tuning vm.swappiness incorrectly may hurt performance or may have a different impact between light and heavy workloads. Changes to this parameter should be made in small increments and should be tested under the same conditions that the system normally operates.
NOTE
if soft_limit_in_bytes is unlimited while limit_in_bytes is set, when processes in this group reach limit_in_bytes, kernel will try to swap some memory of the processes to disk, so that it may be below the limit, but if there is no swap left of the system or it reaches memsw.limit_in_bytes, in these case, one of the process(high score) should be killed by OOM killer.
cgroup subsystem kernel
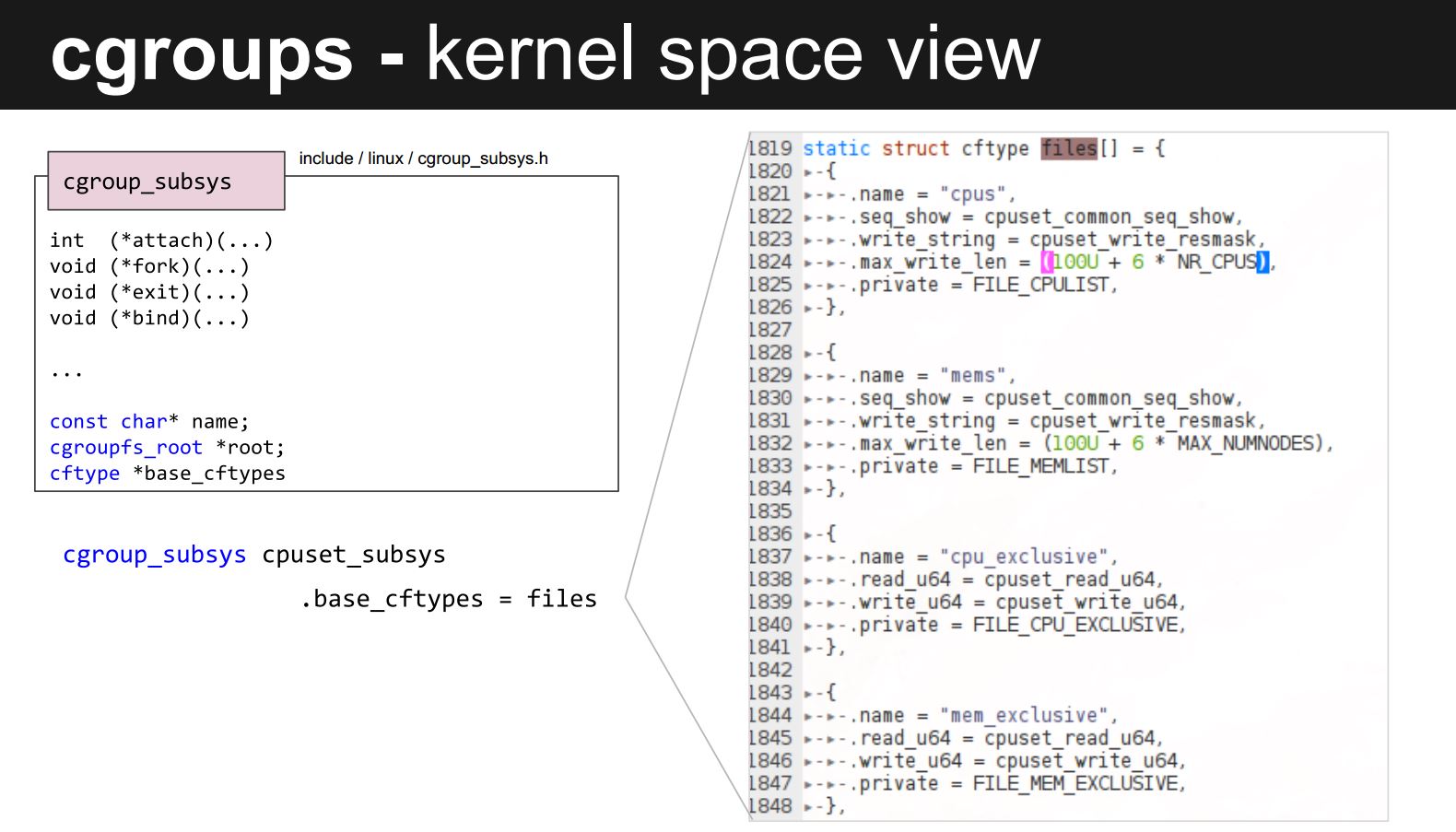
Here is the source code for each subsystem
1 | cpuset_subsys - defined in kernel/cpuset.c. |
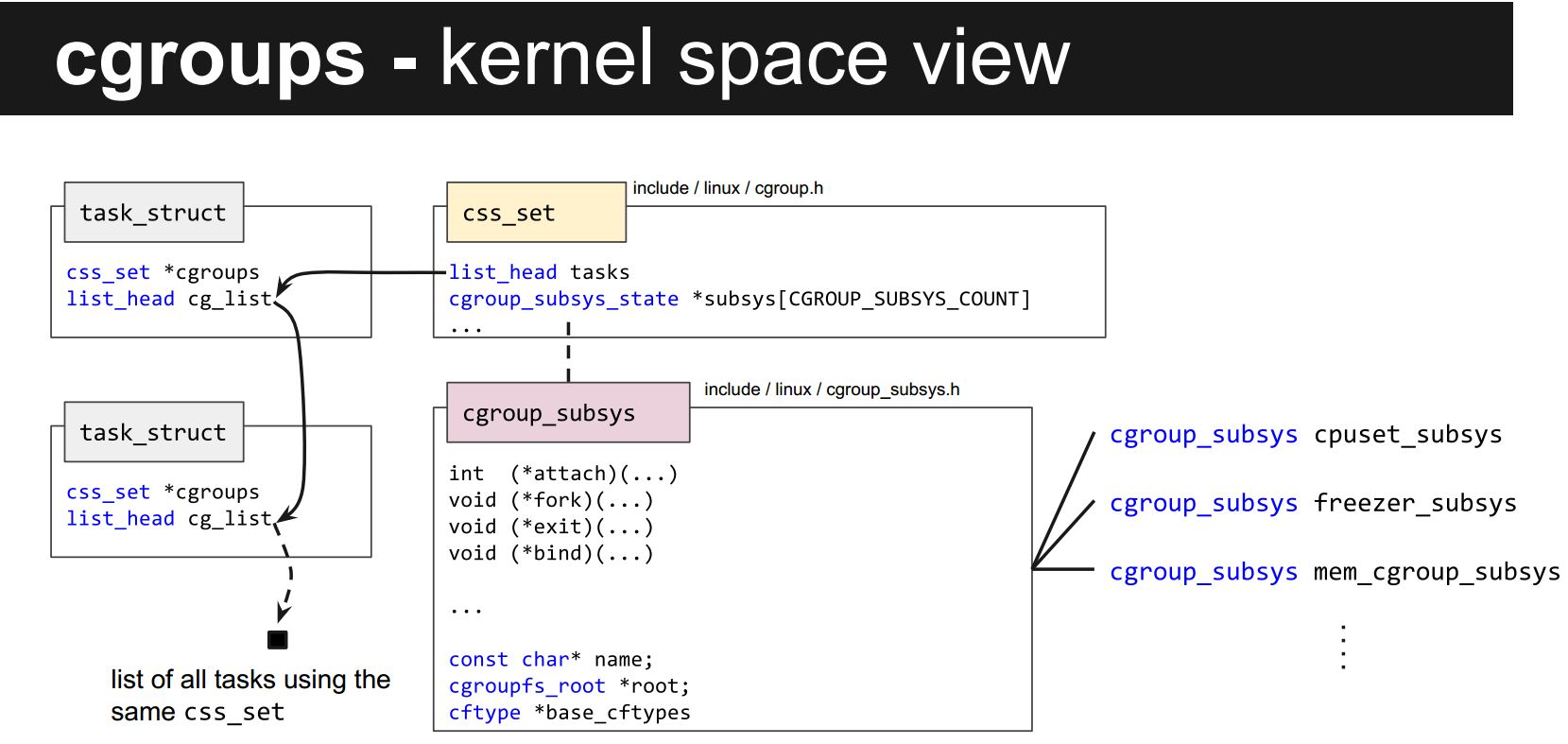
css_set:(set of groups from different subsystems)
When a process forks, the child will be in all the same cgroups that the parent is in. While either process could be moved around, they very often are not. This means that it is quite common for a collection of processes (and the threads within them) to all be in the same set of cgroups. To make use of this commonality, the struct css_set exists. It identifies a set of cgroups (css stands for “cgroup subsystem state”) and each thread is attached to precisely one css_set. All css_sets are linked together in a hash table so that when a process or thread is moved to a new cgroup, a pre-existing css_set can be reused, if one exists with the required set of cgroups
cgroupv2
Why cgroupv2(kernel>=4.5)?
There was a lot of criticism and issues about the implementation of cgroups, which seems to present a number of inconsistencies and a lot of chaos. For example, when creating subgroups (cgroups within cgroups), several cgroup controllers propagate parameters to their immediate subgroups, while other controllers do not. Or, for a different example, some controllers use interface files (such as the cpuset controller’s clone_children) that appear in all controllers even though they only affect one. also due to different subsystem(cpu, memory, blkio), limitation only affect within that subsystem, hence when buffer io is enabled(enabled by default), write/read only happens at page cache, blkio who works at block layer, does not know it, hence can not limit disk io correctly! but with cgroupv2, as memory, blkio can be enabled at same group, so blkio with v2 can works as expected!!!
The biggest change to cgroups in v2 is a focus on simplicity to the hierarchy. Where v1 used independent trees for each controller (such as /sys/fs/cgroup/cpu/GROUPNAME and /sys/fs/cgroup/memory/GROUPNAME), v2 will unify those in /sys/fs/cgroup/GROUPNAME. In the same vein, if Process X joins /sys/fs/cgroup/test, every controller enabled for test will control Process X
For example, in cgroups v2, memory protection is configured in four files:
- memory.min: this memory will never be reclaimed.
- memory.low: memory below this threshold is reclaimed if there’s no other reclaimable memory in other cgroups.
- memory.high: the kernel will attempt to keep memory usage below this configuration.
- memory.max: if memory reaches this level the OOM killer (a system used to sacrifice one or more processes to free up memory for the system when all else fails) is invoked on the cgroup
cgroupv2 usage and redhat cgroupv2 guideline
FAQ
check cgroups of a given process
1 | # cat /proc/$pid/cgroup |
change a cgroup of a given process
change cpu cgroup of given process
1 | # you can create a sub group under a subsystem or under another group |
check root node of particular cgroup(subsystem)
1 | # ls /sys/fs/cgroup/xx |
create cgroup(sub group of a given cgroup subsystem)
1 | create a cpu control group, you can create cgroup alone without process, later on add process to it |
the created cgroup will be deleted after reboot!!!, when created, there is no process in this group
when you delete a cgroup, all its processes are moved to their parent group.
run a program in a given cgroup
1 | $cgexec -g controllers:path_to_cgroup command arguments |